履歴画面で執筆のモチベーションを上げよう
今回は開発途中の新しい画面を公開したいと思います。
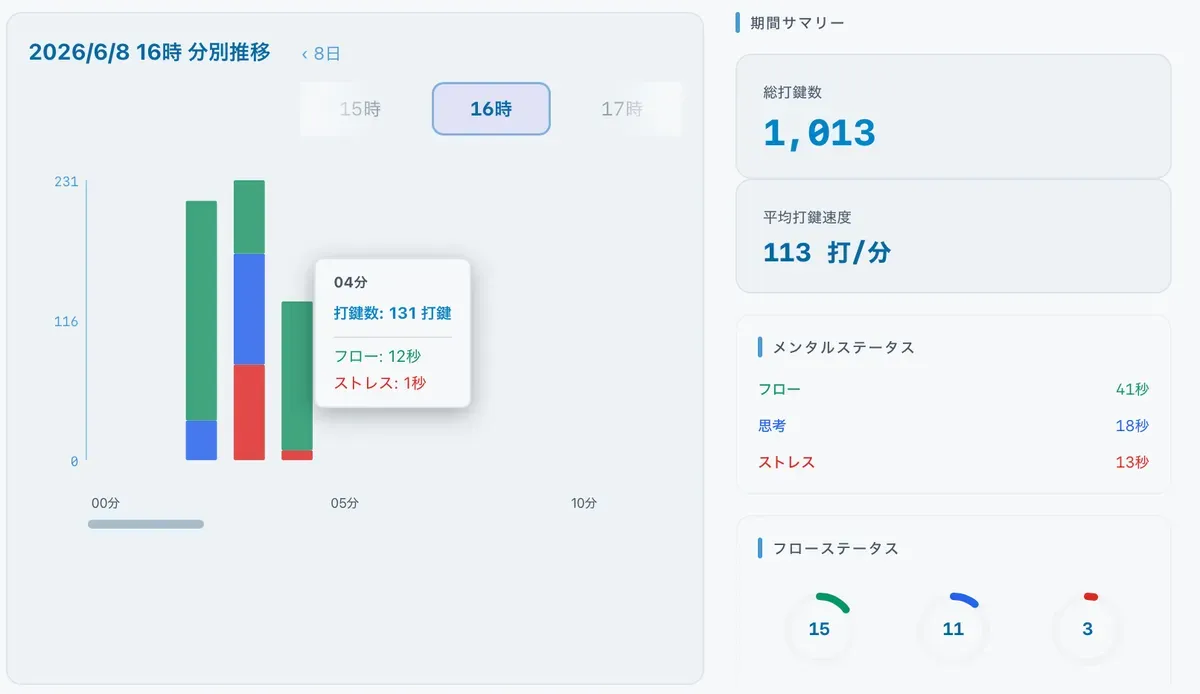
この画面は執筆状態を過去数年分、分単位で確認できるものです。「1年前のあの日、私ってどれくらい書いてたんだろう」そう思ったときにこの画面をみてください。入力した打鍵数やそのときのタイピング速度、そして精神状態までわかります。(もっとたくさんの情報も含まれます!)
以前のブログで、Gamita Novelistには複雑な計算をして小説家の精神状態を理解しようとしていましたね。
そのアイデアをもっと改良して搭載したのが、このメンタルステータス、フローステータスです。
まず、Gamita Novelistの認知システムは3つのレイヤーに分かれています。
L1レイヤー
L1レイヤーとは、高度な計算式で小説家のデータを収集、分析するものです。ブログで紹介したアルゴリズムを改良したものを使っています。この画面には映っておらず、常にバックグラウンドで計算をしてくれています。
D1レイヤー
D1レイヤーは蓄積されたL1レイヤーのデータを瞬時に解析します。L1レイヤーとは別のアルゴリズムによって管理され、画面中央の「フロー:12秒」のように、メンタルステータス項目の細かな秒数を記録していきます。
しかし、注意点があります。本来、フローやストレスという値は秒数で扱うことはできません。脳波で直接測るしか方法がないからです。
様々な検証を行った結果、後述するフローステータスと大きな乖離がなかったことから秒単位で表示することにしました。独自に算出したサンプル値ではありますが、自信の持てる精度になっています。このD1レイヤーをさらにわかりやすくしたものが、リアルタイムでエディタ画面下部に表示されます。画像では「思考状態」になっています。実際に執筆してみて精度を確認してみてください。
O1レイヤー
O1レイヤーはもっと複雑です。
D1レイヤーが簡易的なデータなのに対して、D1レイヤーは適切に集計を行います。
また、その集計方法は項目ごとに異なります。メタアナリシスが存在する学術論文を参考に算出されます。
没入度(フロー理論 )
ミハイ・チクセントミハイが提唱したフロー理論。最も有名な集中力モデルです。スポーツや勉強など、あらゆる場面で活用されています。Gamita Novelistでは15分間隔で評価されます。
思考(デリバレートプラクティス)
K.アンダース・エリクソンのデリバレートプラクティスは、目標設定で有名な理論です。例えばちょっと難しいことに挑戦するだとか、居心地がいい場所からあえて離れる、コンフォートゾーンからの脱却が有名ですね。
ストレス(認知的負荷理論 )
ジョン・スウェラーのワーキングメモリーは誰もが経験したことがあるはずです。頑張っても勉強しても記憶できない。一人で作業しているとそわそわして、つい別のことをやりたくなる。寝たほうが記憶の定着がいい!
どんなに執筆意欲があっても、脳疲労や眠気、疲れなど様々な要件が重なるとストレスになります。
実はこれら3つは全く別の指標であり、本来は1つの項目としてまとめるべきではありません。例えばフロー状態と、居心地の良さは関係ありませんよね。ではなぜ、Gamita Novelistではこのような形を取ったのか。
これは帰納法と演繹法の違いです。
学術論文やNASA-TLXなど、極めて信頼性があるストレステスト、あるいはフロー状態の識別は具体的な数値やヒヤリングが必要です。これは証拠集めをして、一定のルールのもとで判断を下します。しかし、これが成功するのは正しいデータを正確に集める工程が必要です。Gamita Novelistではキーボードを打つという単純な動作が重要になってきます。執筆するたびにアンケートを取るわけにはいきませんよね。
そこで、フローステータスでは、演繹的なアプローチを取っています。L1レイヤーで取得した膨大なデータからそれぞれの理論にまたがる仮説を見つけ出します。
これを仮説推論(アブダクション)といいます。これは、思いつきや適当に回答をするということではありません。むしろ、従来の帰納法や演繹法よりも高い成果をあげることができます。
AIや医療の診断システムがまさに仮説推論を使っています。AIに話しかけると、母国語で喋ってくれますよね。これは、AIが渡された文字から「おそらくこの文字を使っているのだから、この母国語がいいのだろう」と推論をするからです。もしこれが帰納法であれば、ユーザーにアンケートを取らないと回答の保証ができないため、会話が成立しません。
AIは間違った回答をします。だからこそ高度な会話が成立するわけです。フローステータスもまた、完全な数値、学術的な証明ができない代わりに、高い精度で小説家の状態を理解することができます。
実はGamita Novelistの認知システムには、個人の学習データを反映できる仕組みがあります。これはまさにAIと同じ仕組みで、提供してくださるユーザーが増えれば、より正確な回答をすることができます。(もちろん、提供は任意であり強制は絶対にしません)
また、学習処理には一般的に知られているAI(例えばGemini,Claude,DeepSheek)は使用していません。完全にオリジナルの機械学習を用いて開発しています。