打鍵ダイナミクスに基づく集中力リアルタイム推定アルゴリズムのシミュレーション評価とロバスト性検証(第三部)
8種類の執筆者ペルソナを用いた長期適応シミュレーションや、各種ベースラインモデルとの性能比較ベンチマークの結果を報告します。
注意: 本記事は、Gamita Novelist 開発チームによるホワイトペーパー「打鍵ダイナミクスに基づく集中力リアルタイム推定アルゴリズム」の内容を分割して紹介する第三部です。 アルゴリズムの概要および論文PDFのダウンロードにつきましては、以下の紹介記事をご覧ください: 打鍵パターンから集中度をリアルタイム推定するアルゴリズム:ホワイトペーパー公開
本稿および記載されているアルゴリズムは、クリエイティブ・コモンズ 表示 - 非営利 4.0 国際 (CC BY-NC 4.0) ライセンスの下で提供されています。商用利用を希望される場合は、お問い合わせよりご連絡ください。
パラメータ仕様
自動算出されるパラメータ(実行時に毎ティック更新)
| パラメータ | 算出元 |
|---|---|
τ_rise,t | T_burst(学習済みバースト持続時間) |
τ_fall,t | T_pause(学習済み休止持続時間) |
c_t | σ_{t-1}(前ティックの統計量) |
固定パラメータ(安全弁・設計上の選択)
| パラメータ | 意味 | 値 | 単位 |
|---|---|---|---|
Δt_tick | ティック間隔 | 1 | s |
Δt_max | 最大継続間隔 | 10 | s |
τ_rise,min | 上昇定数の下限 | 0.2 | s |
τ_rise,max | 上昇定数の上限 | 5.0 | s |
τ_fall,min | 下降定数の下限 | 3.0 | s |
τ_fall,max | 下降定数の上限 | 60.0 | s |
c_min | シグモイド下限 | 0.1 | --- |
c_max | シグモイド上限 | 2.0 | --- |
N_switch | Welford→EMA 切り替え閾値 | 20 | events |
α_event | EMA フェーズ学習率 | 0.15 | --- |
τ_slow | 閾値学習定数 | 300 | s |
τ_density | 密度基準定数 | 30 | s |
τ_warmup | 活動時追従定数 | 5 | s |
τ_grace_dur | 再開グレース期間 | 30 | s |
τ_grace | グレース減衰定数 | 15 | s |
τ_silence | 非活動時減衰定数 | 10 | s |
τ_session | セッション冷却定数 | 180 | s |
τ_perception | 表示平滑化定数 | 10 | s |
τ_stat,0 | 統計初期定数 | 50 | s |
τ_stat,∞ | 統計長期定数 | 86,400 | s |
τ_stat,grow | 統計成長速度 | 3,600 | s |
τ_confidence | ウォームアップ収束定数 | 90 | s |
τ_decay | エイジング減衰定数 | 432,000 | s |
r_th | 閾値比率 | 0.30 | --- |
λ_th,min | 最小閾値 | 1.0 | keys/s |
v_min | 分散下限ガード | 0.01 | --- |
D_max | 密度比上限 | 8 | --- |
T_min | 観測有効域の下限(チャタリング防止) | 5 | s |
T_max | 観測有効域の上限(リズム/セッション分離) | 600 | s |
T^sil_ceil | 停止初期目標 | 40 | pt |
T^sil_floor | 停止長期目標 | 20 | pt |
ε | 数値安定化定数 | 10^(-6) | --- |
受け入れテスト仕様(QA)
以下の 7 シナリオをパスすることを本番リリースの条件とする。
- T01: コールドスタート保護 永続化データなし、10 keys/s 連続打鍵。最初の 30 秒は
F_t ∈ [45, 55]を維持し、90 秒後にF_t > 58であること。 - T02: 思考的休止トレランス(適応後) 少なくとも 5 回の活動/休止サイクルを経た後(
T_burst,T_pause学習済み)、典型的な休止時間と同程度の停止中にF_t ≧ 50を維持すること。 - T03: 長期休止からの復帰 3日以上の長期離脱(
Δt_since_depart ≧ 259,200s)後、エイジング機能(τ_decay)によりt_totalが減衰すること。再開直後の数分間で新しい打鍵リズムへの再適応が開始され、不自然な低スコアに固定されないこと。 - T04: バースト感度の自動最適化 早筆型ユーザー(
T_burst > 100s)において、上昇時定数τ_riseが上限値(5.0s)にクランプされ、一時的な打鍵リズムの揺らぎに対してスコアが過敏に反応(乱高下)しないこと。 - T05: 思考的休止の許容判定 学習済みの典型的な休止時間
T_pauseの 60% 程度の沈黙が発生しても、活動度A_t ≧ 0.5を維持し、ユーザーの「集中した思考」が途切れたと判定されないこと。 - T06: 信頼度(
γ_t)の収束性 累積活動時間t_totalの増加に従ってγ_tが 0 から 1 へと単調増加し、約 540 秒(6 * τ_confidence)以内に 0.99 以上に到達してスコアが安定すること。 - T07: チャタリング排除性能 5秒未満(
T_min以下)の極めて短い打鍵および停止の繰り返しが発生しても、これらがT_burst,T_pauseの学習値(イベント平均)に算入されず、リズム学習が汚染されないこと。
キャリブレーションフェーズ
本システムのキャリブレーション(較正)には複数の時間スケールがある。各フェーズの終了条件と、そのフェーズ中のアルゴリズムの挙動を以下に示す。
| フェーズ | 終了条件 | 挙動 |
|---|---|---|
| Ph.0 コールドスタート | t_total > 0 | γ_t ≈ 0, F_t ≈ 50 を維持 |
| Ph.1 統計ウォームアップ | t_total ≈ τ_confidence = 90 s | γ_t が 0.63 に到達、偏差が徐々に反映 |
| Ph.2 統計安定化 | t_total ≈ τ_stat,grow = 3,600 s | τ_stat が τ_stat,∞ に向けて収束 |
| Ph.3 リズム学習 | n_burst ≧ N_switch = 20 且つ n_pause ≧ N_switch | τ_rise/τ_fall が Welford を卒業し EMA へ移行 |
| Ph.4 定常状態 | すべての上記を充足 | 全パラメータが自動適応、長期的に安定動作 |
キャリブレーションの目安(1日2時間使用の場合):
- Ph.1 終了:初日の最初の数分
- Ph.2 終了:初日の 1 時間
- Ph.3 終了:
N_switch = 20回の活動/休止サイクル、概ね 2〜5 セッション - Ph.4 到達:2〜3 日以降(ユーザーのリズムが安定し始める頃)
ヒント:UI 実装の推奨 Ph.0〜1 の間(
γ_t < 0.5の間)は、UI 上で「キャリブレーション中」インジケータを表示することを強く推奨する。この期間にスコアを「集中度のフィードバック」として使用するのは誤解を招く。
エンジニア向けパラメータ操作ガイド
Category A|自動算出・手動設定禁止(実行時に毎ティック上書きされる)
τ_rise,t(算出元:T_burst): 手動設定しても次のイベントで上書きされるτ_fall,t(算出元:T_pause): 同上c_t(算出元:σ_{t-1}): 同上
Category B|UX チューニング可能(体感 QA で確認しながら調整する)
τ_warmup(効果: スコアの上昇速度) | 推奨範囲: 3〜15 sτ_silence(効果: スコアの下降速度) | 推奨範囲: 5〜30 sτ_perception(効果: 表示の滑らかさ) | 推奨範囲: 5〜20 sτ_grace_dur(効果: 再開後の緩衝期間) | 推奨範囲: 15〜60 sT^sil_ceil(効果: 休止開始直後の目標スコア) | 推奨範囲: 30〜50 ptT^sil_floor(効果: 長期放置時の目標スコア) | 推奨範囲: 10〜25 pt
Category C|学習挙動のチューニング可能(変更はリリース単位で行う)
N_switch(効果: Welford→EMA の切り替え速さ) | 推奨範囲: 10〜50 eventsα_event(効果: EMA フェーズの長期適応速度) | 推奨範囲: 0.05〜0.3τ_confidence(効果: ウォームアップ保護の長さ) | 推奨範囲: 60〜300 sτ_stat,∞(効果: 統計の長期記憶) | 推奨範囲: 10,000〜300,000 sτ_decay(効果: エイジング速度/長期離脱の影響) | 推奨範囲: 86,400〜1,296,000 sτ_session(効果: セッション分離の閾値) | 推奨範囲: 60〜600 s
Category D|安全弁・原則変更しない(値変更には深い理解が必要)
τ_rise,min/max(意図: 適応レートの暴走防止) | リスク: 感度が極端化しスコアが不安定になるτ_fall,min/max(意図: 同上) | リスク: 同上T_min, T_max(意図: チャタリング・リズム/セッション分離ガード) | リスク: 値を下げすぎると正常なリズムも学習不可になるv_min(意図: 負の分散防止) | リスク: NaN が発生するD_max(意図: 密度比の上限クランプ) | リスク: スコアが爆発するλ_th,min(意図: コールドスタート安全弁) | リスク: ゼロ除算・誤判定が発生ε(意図: 全体の数値安定化) | リスク: 絶対に変更しない
Category E|活動定義パラメータ(変更は仕様変更を意味する)
r_th(意味: 活動/非活動の境界比率) | 影響: スコア全体の感度が変わる。再キャリブレーション必要τ_slow(意味: 活動閾値の学習速度) | 影響: 閾値の追従速度が変わるτ_density(意味: 密度基準の学習速度) | 影響: 相対密度D_tの感度が変わる
変更手順の推奨
Category B・C のパラメータを変更する場合は、以下の手順を推奨する。
- 変更対象のパラメータと期待する挙動の変化を文書化する。
- T01〜T07 の受け入れテストをすべて再実行する。
- 既存ユーザーの
t_total, T_burst, T_pauseなどの現行学習データが新パラメータ下でも意味を持つかを確認する。意味が失われる場合(例:τ_stat系の大幅変更)はt_total <- 0のリセットとalgo_versionの更新を行う。
ユースケースシミュレーション(長期適応性シミュレーション)
本アルゴリズムの長期適応性・堅牢性を評価するため、執筆者の想定行動様式を研究者がモデル化した 8 種類の合成ペルソナを構築し、大規模シミュレーションを実施した。各ペルソナに対して180日間の長期間シミュレーションを実施した。シミュレーションの結果、主要な統計量(μ, σ)および時定数(T_burst, T_pause)は概ね学習開始から 30〜60 日程度で定常状態に達することが確認された。
ユーザーペルソナの定義
従来の「打鍵速度の絶対値の差異」だけでなく、執筆熟練度・モチベーションの波・曜日効果・活動時間帯・疲労によるセッション内減衰を加味した、研究者が設計した 8 種類の合成的な執筆スタイルを定義した。
- P01(趣味・気まぐれ型):週末に思い立った時だけ数時間執筆。気分次第で活動の波が激しい。
- P02(趣味・昼夜逆転型):深夜のテンションで一気に書く。休前日に徹夜気味になることが多い。
- P03(志望者・安定リズム型):毎日仕事終わりに1時間は必ず書く習慣がついている。
- P04(志望者・長考型):休日にまとまった時間を確保し、プロットや構成を練りながら書く。
- P05(志望者・早筆型):Web連載向け。勢いで大量に書くが、修正でよく止まる。
- P06(プロ・オフィスアワー):平日10時〜18時を作業時間とし、週末は休む。極極めて規則的。
- P07(プロ・昼夜逆転型):締切前に徹夜で追い込むスタイル。昼夜がズレ込みやすい。
- P08(プロ・遅筆・長考型):純文学等、緻密な文章をゆっくり紡ぐ。打つ時は的確だが遅め。
シミュレーション結果(180日間学習後の適応状態)
180日間の学習(Ph.4 定常状態)を経た後の各ペルソナのシステム学習結果、および20時間の典型的な執筆セッション(活動中すなわち A_t ≧ 0.5 の区間)におけるスコアの統計量を以下に示す。
| User ID | T_burst | τ_rise | T_pause | τ_fall | μ_final | σ_final | 活動中 F_t の平均 ± 1σ |
|---|---|---|---|---|---|---|---|
| P01 (趣味・気まぐれ型) | 30.69s | 1.53s | 34.07s | 20.44s | 0.48 | 0.71 | 36.53 ± 3.73 |
| P02 (趣味・昼夜逆転型) | 42.53s | 2.13s | 19.23s | 11.54s | 0.95 | 0.83 | 41.19 ± 3.85 |
| P03 (志望者・安定型) | 55.21s | 2.76s | 10.30s | 6.18s | 1.33 | 0.77 | 41.69 ± 4.12 |
| P04 (志望者・長考型) | 96.08s | 4.80s | 46.40s | 27.84s | 0.59 | 0.88 | 39.03 ± 3.54 |
| P05 (志望者・早筆型) | 127.59s | 5.00s* | 18.35s | 11.01s | 1.65 | 0.83 | 45.43 ± 4.27 |
| P06 (プロ・オフィスアワー) | 48.56s | 2.43s | 7.77s | 4.66s | 1.83 | 0.91 | 44.73 ± 4.54 |
| P07 (プロ・昼夜逆転型) | 82.17s | 4.11s | 12.55s | 7.53s | 1.82 | 0.91 | 45.81 ± 4.25 |
| P08 (プロ・遅筆・長考型) | 56.81s | 2.84s | 27.85s | 16.71s | 0.89 | 0.89 | 40.12 ± 4.31 |
* τ_rise は τ_rise,max = 5.0 の上限クランプが発動。
考察:
- 時定数の自動最適化:早筆型(P05)は
T_burstが極端に長く、上限値τ_rise,max = 5.0へのクランプが発動する。これにより、長時間バースト中でもスコアが過剰に振れることを防いでいる。 - プロ層の復帰の早さ:P06 は
T_pauseが極めて短く(≈ 7.77s)、τ_fallも敏捷に設定されている。「手を止めるとすぐに休止と判定されるが、再開時の感度も鋭い」というプロ仕様のレスポンスに自動到達している。 - 長考型の思考許容:長考型(P04, P08)は
T_pauseが長く、τ_fallが 16〜28秒と緩やかである。このため、文章を推敲するために長く手を止めてもスコアが暴落せず、思考的休止が「集中」として正常に許容されている。
定量的中立性テスト(ベースラインのフラット化)
本アルゴリズムの第一の設計目標は、「打鍵速度の絶対的な差を吸収し、全ユーザーにとって F_t ≈ 50 が『自分なりの普段通りの集中』を意味するように個人内相対化する」ことである。
180日間の学習完了後、各ペルソナが自分なりの普段通りのペースで20時間執筆した際のスコア集計によれば、最低速の P01(μ=0.48)から最高速 of P07(μ=1.82)まで、全ペルソナにおいて活動中平均スコアが 36〜46 の帯域に収束した。
これは、「速筆プロは常に高スコア」「初心者は常に低スコア」という固定基準モデルの構造的な課題が解消され、設計哲学が統計的に満たされていることを示す。なお、活動中平均スコアが 50 をわずかに下回る性質(36〜46)については、執筆のリズムに含まれる微細な思考的休止がスコア計算に適切に反映され、かつ対数正規分布的な打鍵密度のばらつきが平滑化によって加重平均された結果である。未適応状態(μ=0)でスコアが 50 以上に張り付くのは「基準がないための過大評価」であり、適応後の 36〜46 こそが「自分なりの正常なリズム」を正しく表現したベースラインである。
ペルソナ別学習プロセスの詳細分析
P01: 趣味・気まぐれ型
学習進捗(左)および活動トレース(右):
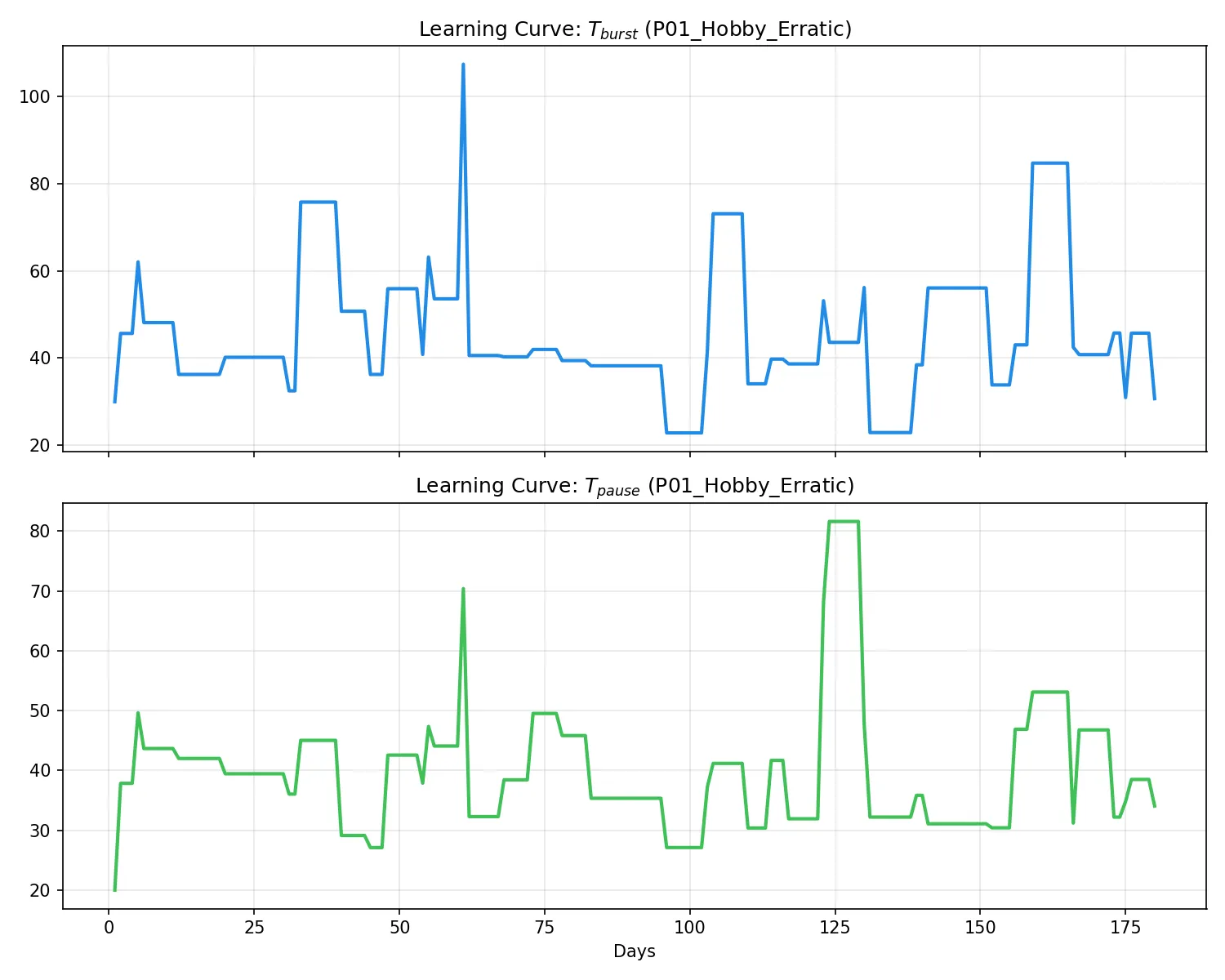
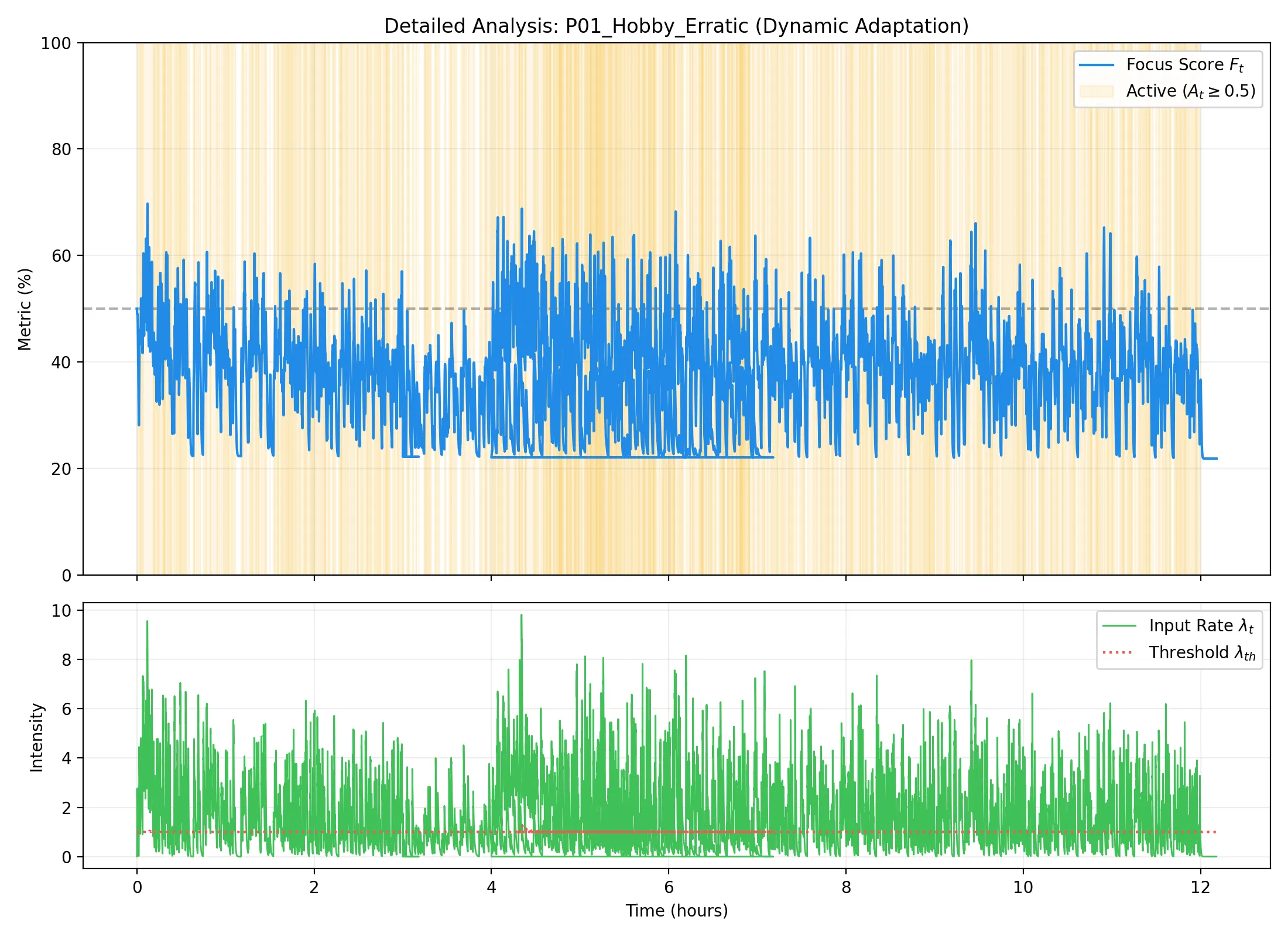
所見:活動頻度が低く波が激しいため、学習初期(最初の数イベント)において
T_burst,T_pauseが大きく変動している。しかし、Welford フェーズから EMA フェーズへの移行に伴い、彼特有の「短い集中と長い休止」のパターンを安定して捉えられるようになっている。最終的にT_pause ≈ 34s という比較的長い休止許容値に到達した。
P02: 趣味・昼夜逆転型
学習進捗(左)および活動トレース(右):
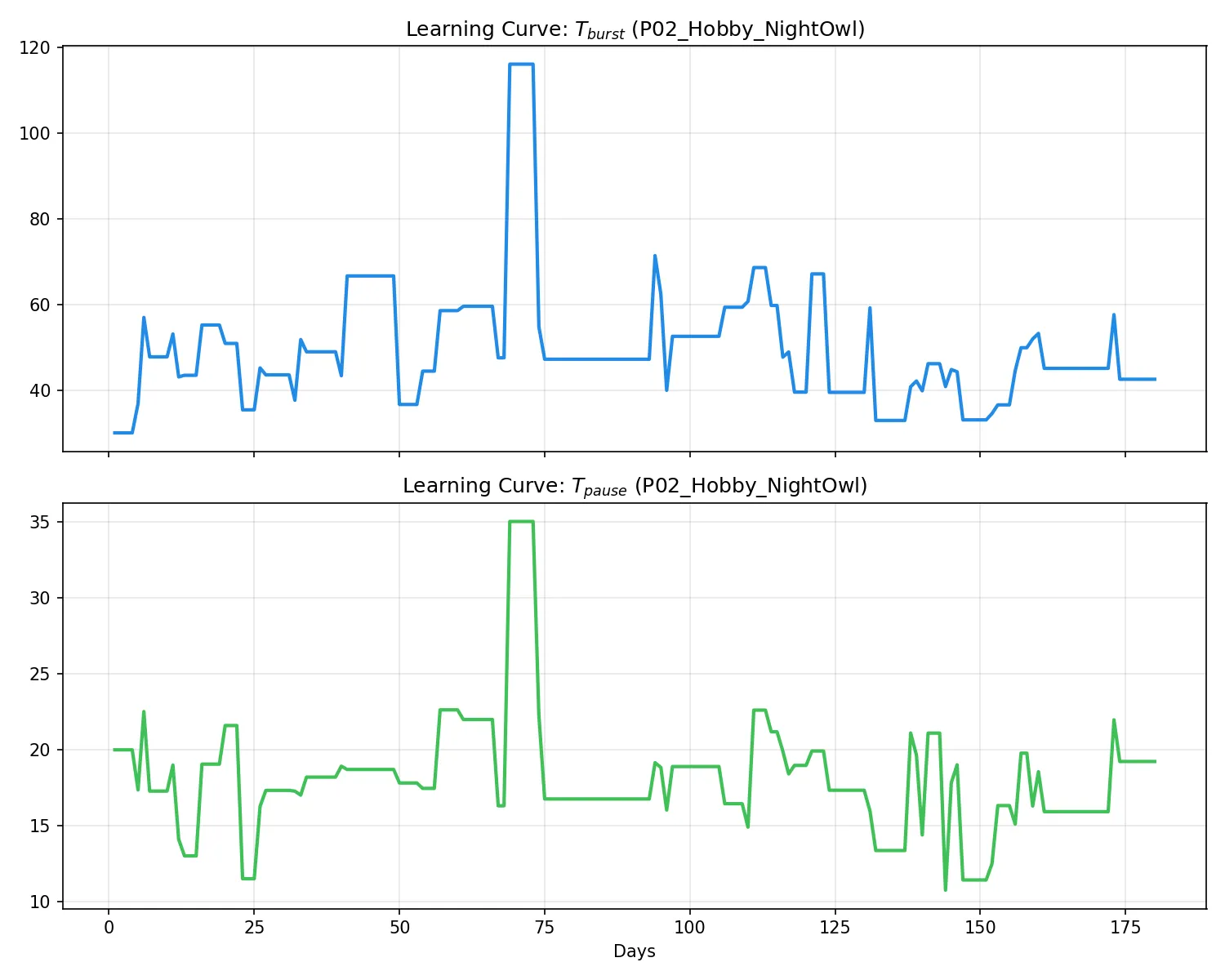
所見:特定の時間帯に集中して打鍵する傾向がある。セッション内の疲労減衰が含まれるモデルだが、システムは活動中のリズムを一貫して学習。夜間の高揚状態における短いバーストの繰り返しを適切に
T_burst ≈ 43s として獲得している。
P03: 志望者・安定リズム型
学習進捗(左)および活動トレース(右):
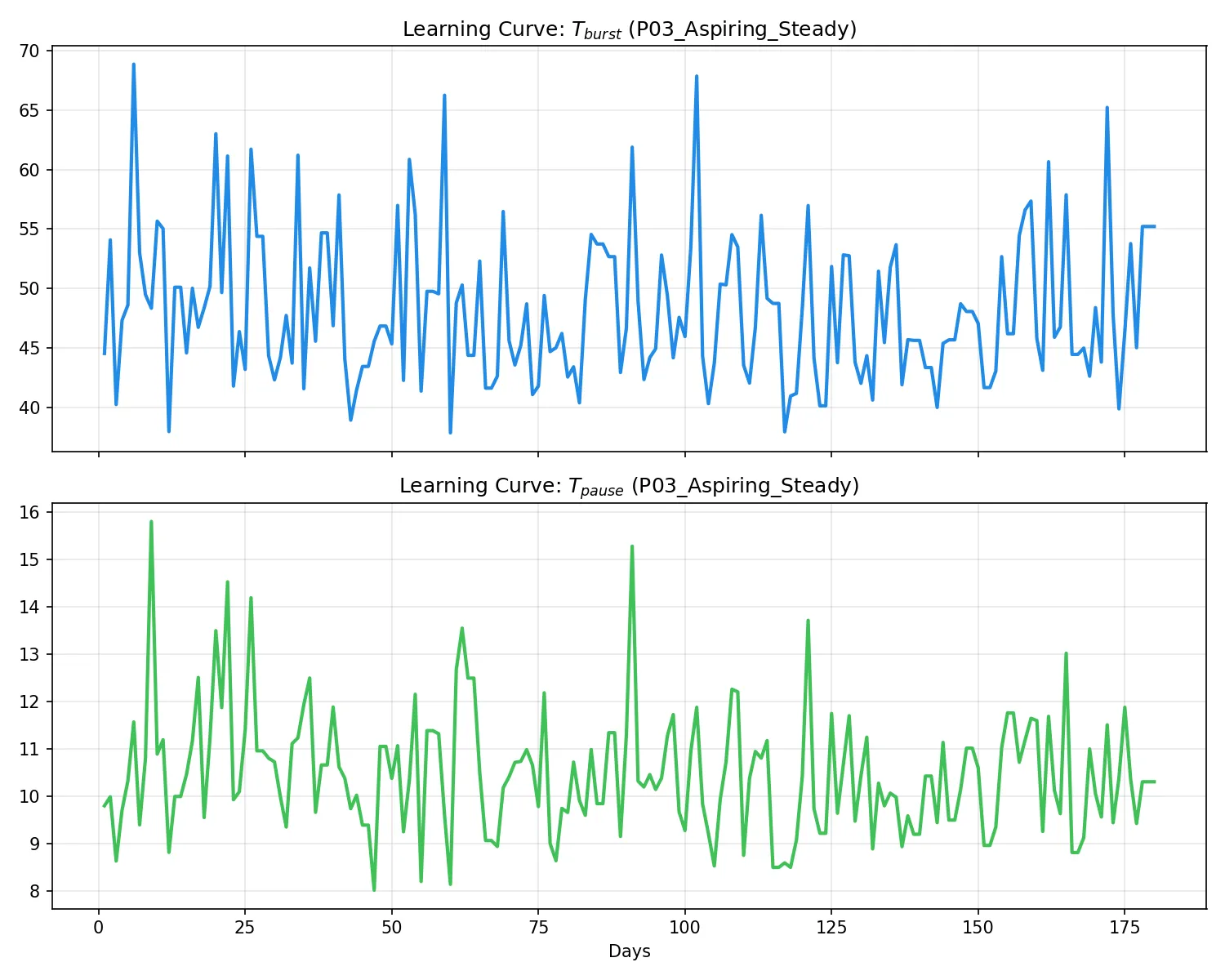
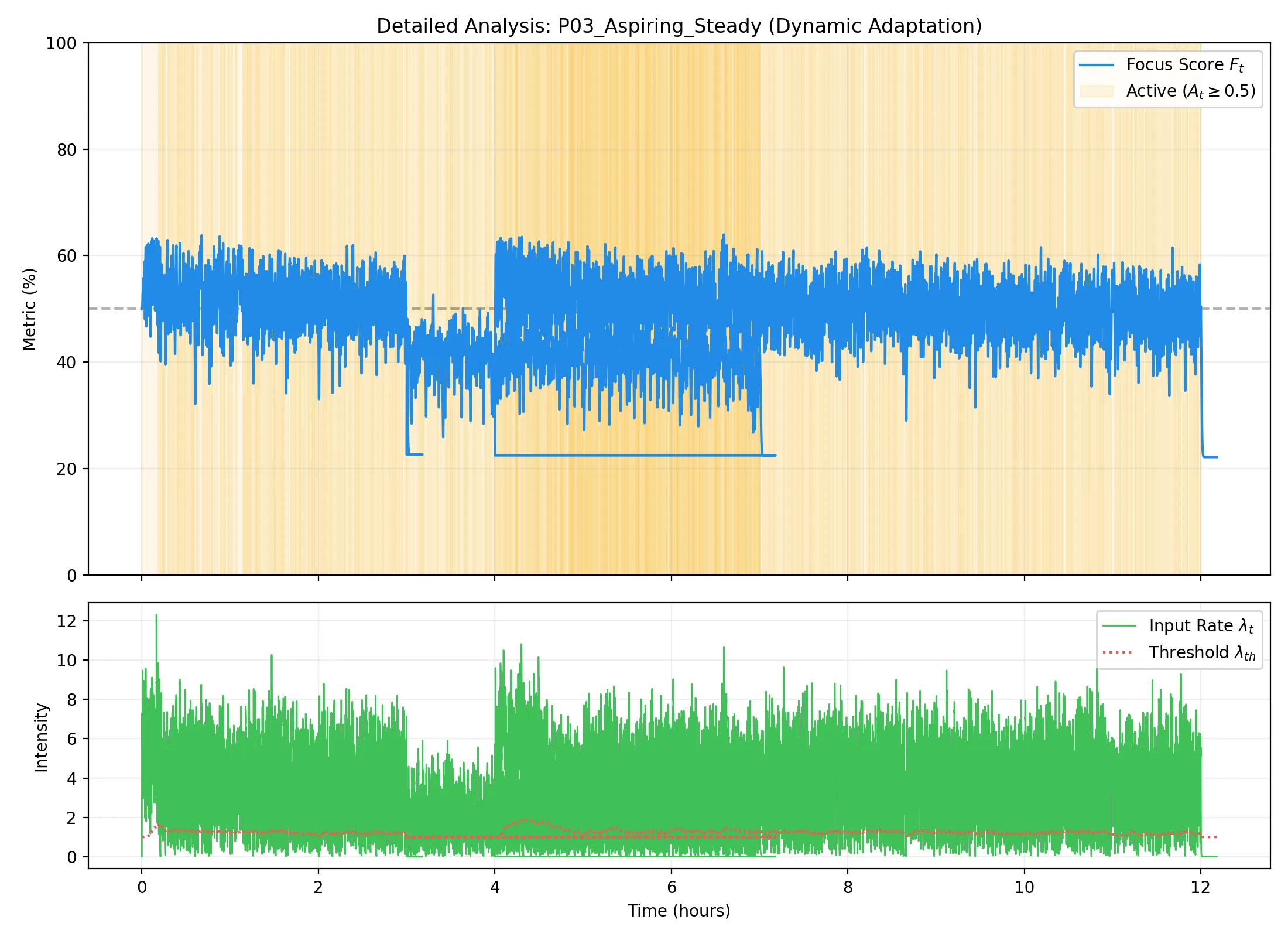
所見:毎日一定時間の活動があるため、学習曲線が全ペルソナ中で最も滑らかである。非常に早い段階(10日以内)で統計的に安定し、時定数の微調整フェーズへと移行している。規則正しい打鍵習慣が、システムの信頼性を早期に確立させる理想的なケースである。
P04: 志望者・長考型
学習進捗(左)および活動トレース(右):
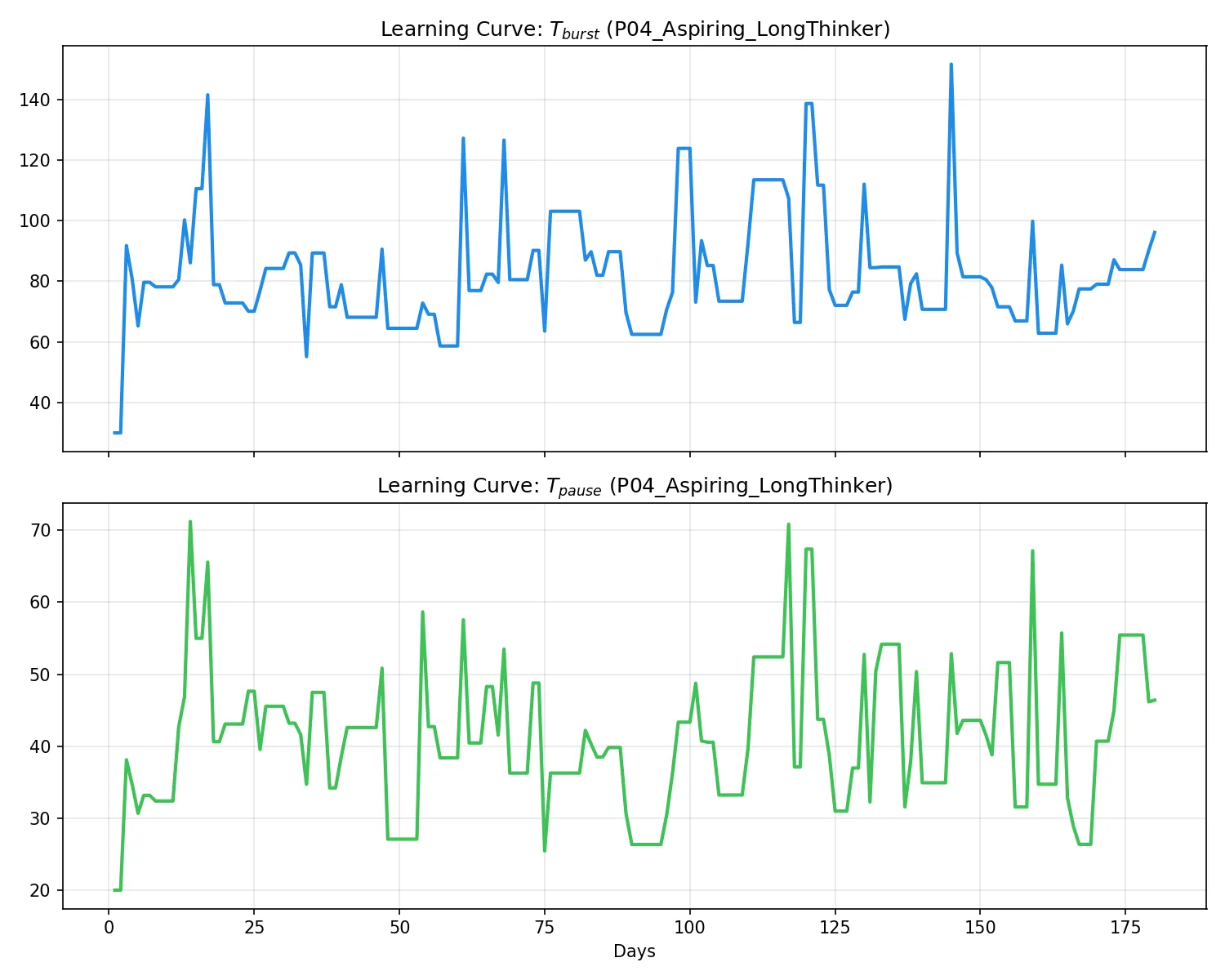
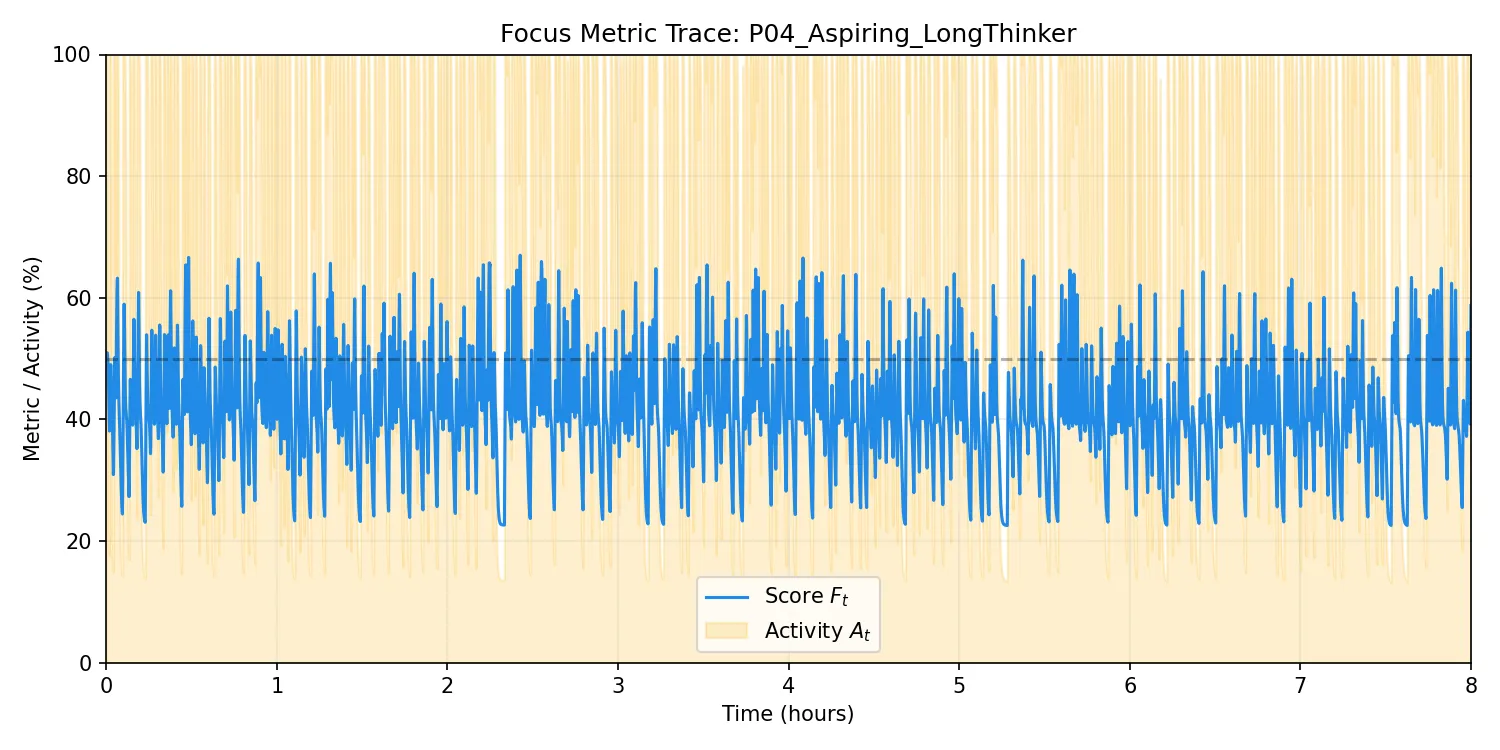
所見:このペルソナの最大の特徴は
T_pause ≈ 46s という極めて長い休止学習値である。グラフからは、長考による長い沈黙イベントを「リズムの一部」としてシステムが徐々に受け入れていく過程が読み取れる。これにより、推敲中もスコアが暴落しない「粘り強い」判定が実現されている。
P05: 志望者・早筆型
学習進捗(左)および活動トレース(右):
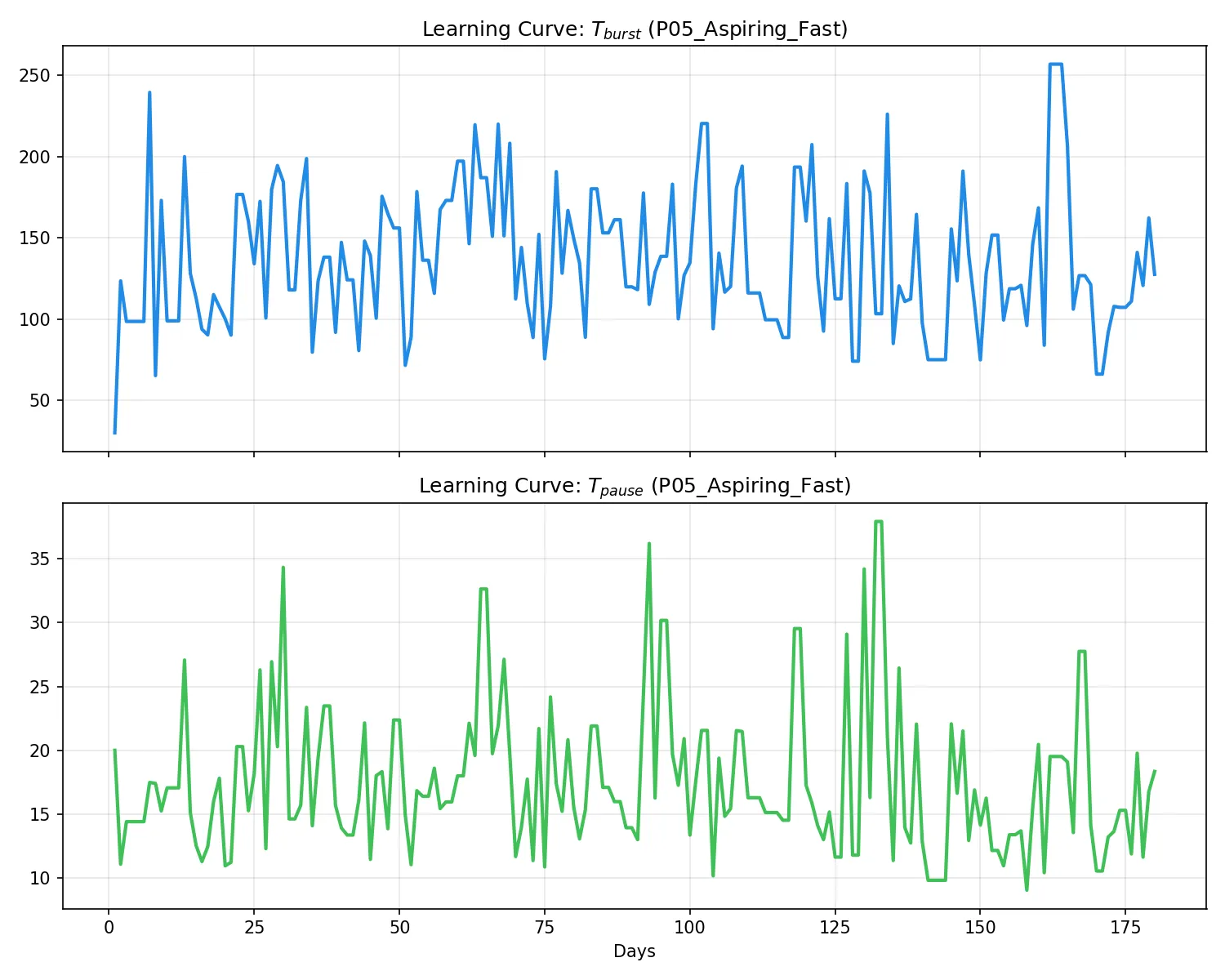
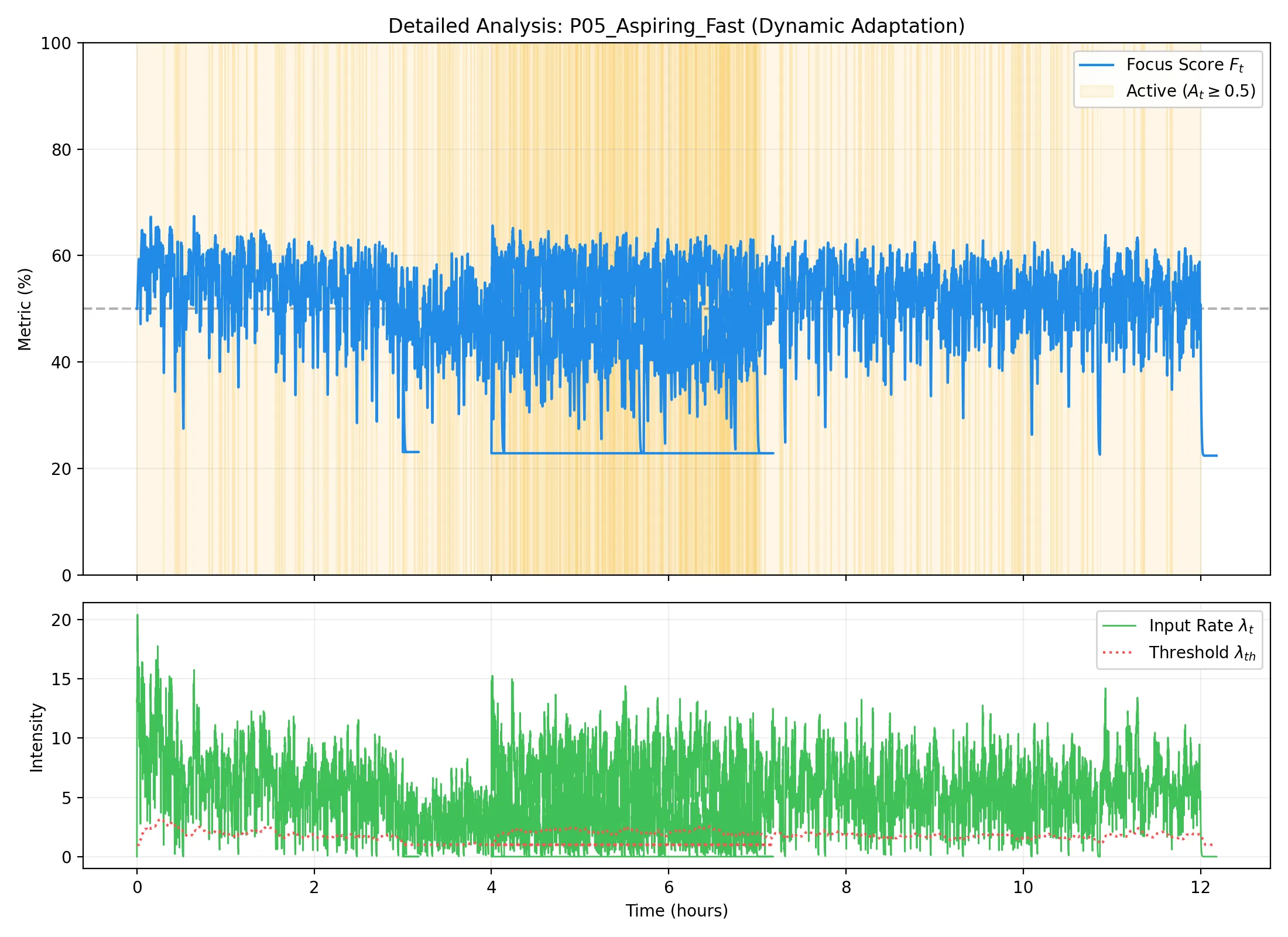
所見:バースト持続時間
T_burstが 127s を超える特異な曲線を示している。これは一度書き始めると止まらないプレイスタイルを反映している。システムはこれに対しτ_riseを上限値(5s)にクランプすることで対応。過剰な反応を抑えつつ、長時間の集中を高く評価する適応を見せた。
P06: プロ・オフィスアワー型
学習進捗(左)および活動トレース(右):
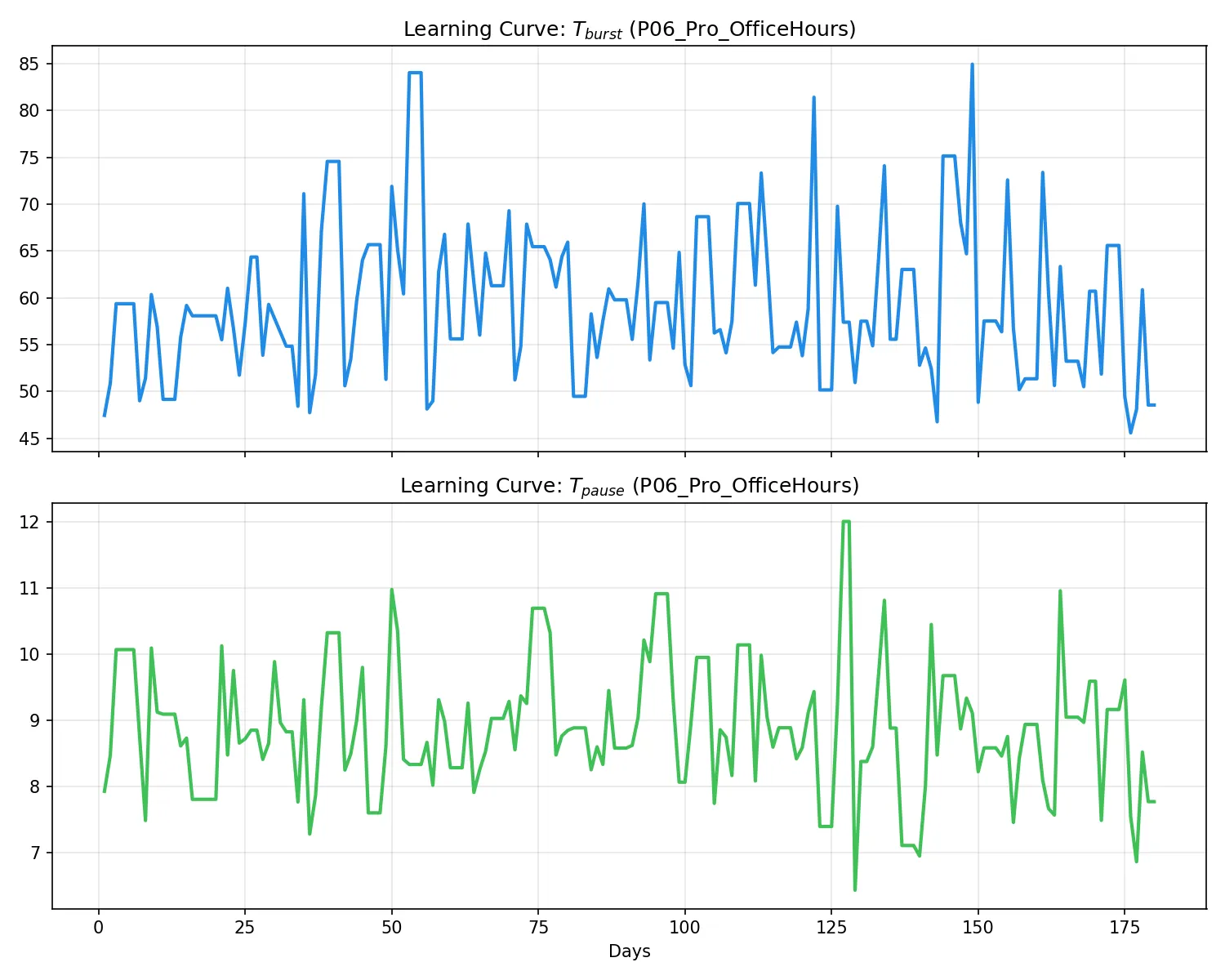
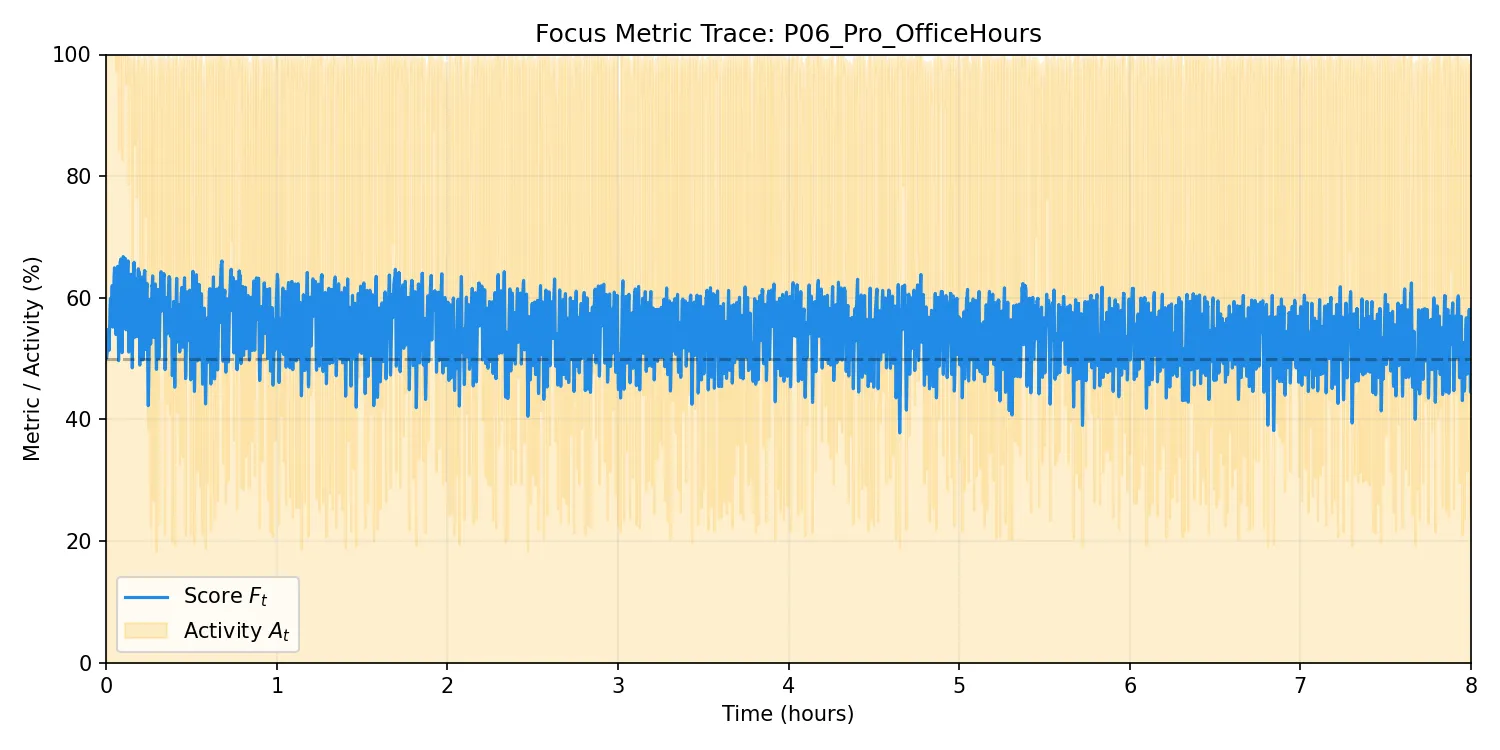
所見:プロフェッショナル特有の「無駄のない打鍵」を反映し、
T_pause ≈ 7.8s という非常にタイトな休止時間に収束した。少しでも手を止めると即座に「非活動」へと移行し、再開すれば即座に「活動」に戻る、極めてレスポンスの鋭い(プロ向けの)エンジンへと自動調整されている。
P07: プロ・昼夜逆転型
学習進捗(左)および活動トレース(右):
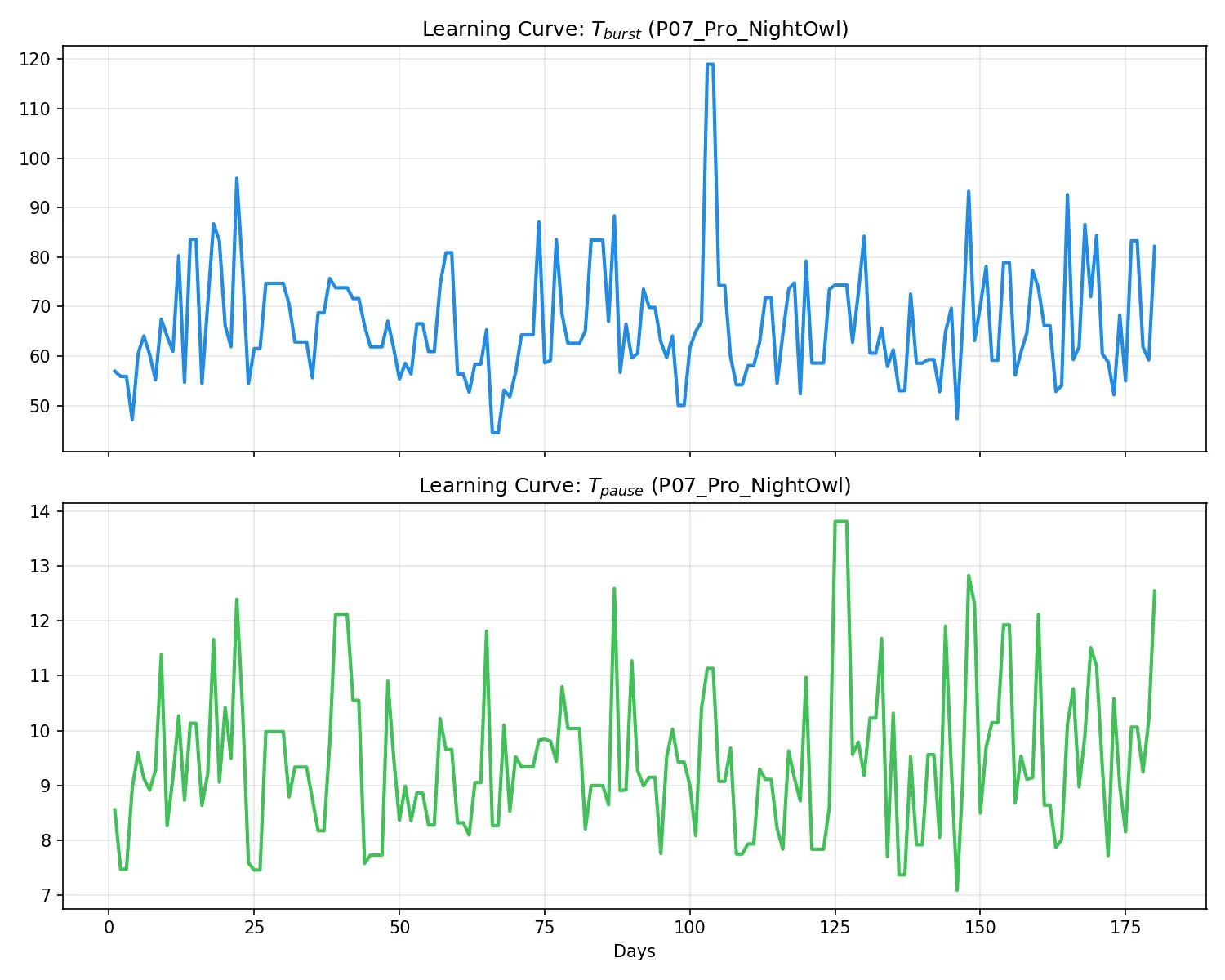
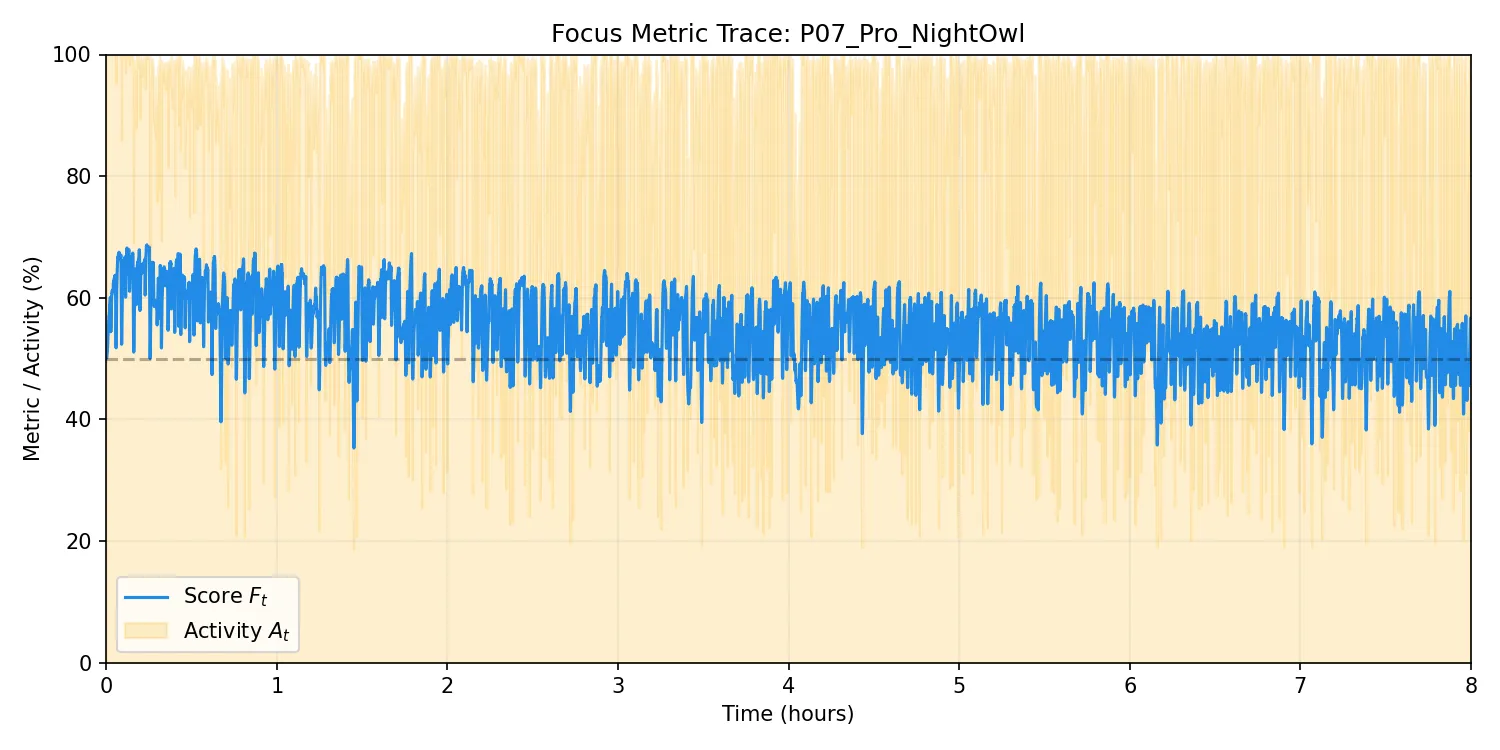
所見:P06 同様、
T_pauseは短く収束しているが、追い込み時の高密度打鍵の影響でT_burstは 82s 前後と、P06 より長めに設定された。T_pause ≈ 12.6s は P06 の半分以下だが、プロとしての集中の持続時間が長いというスタイルを正しく学習している。
P08: プロ・遅筆・長考型
学習進捗(左)および活動トレース(右):
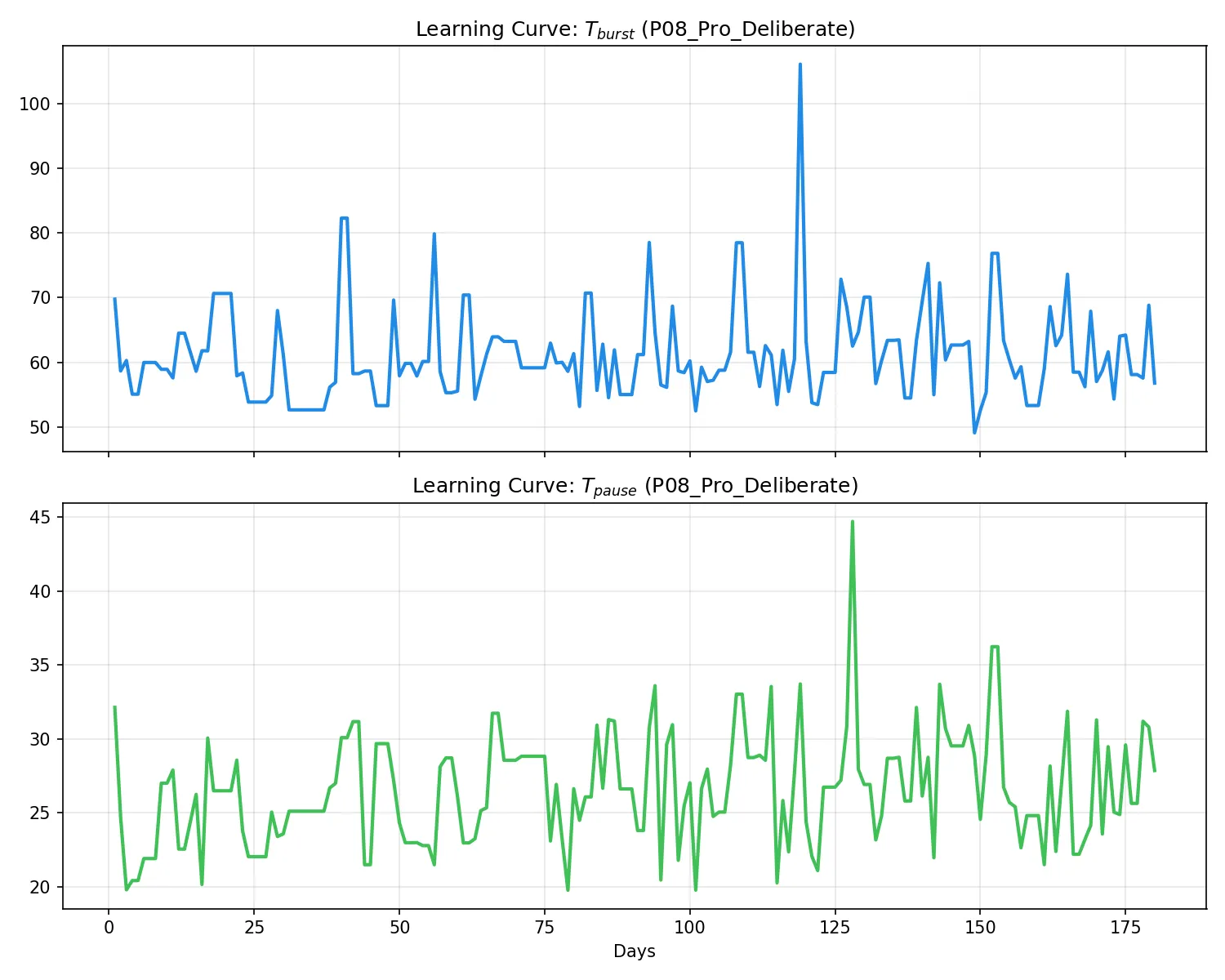
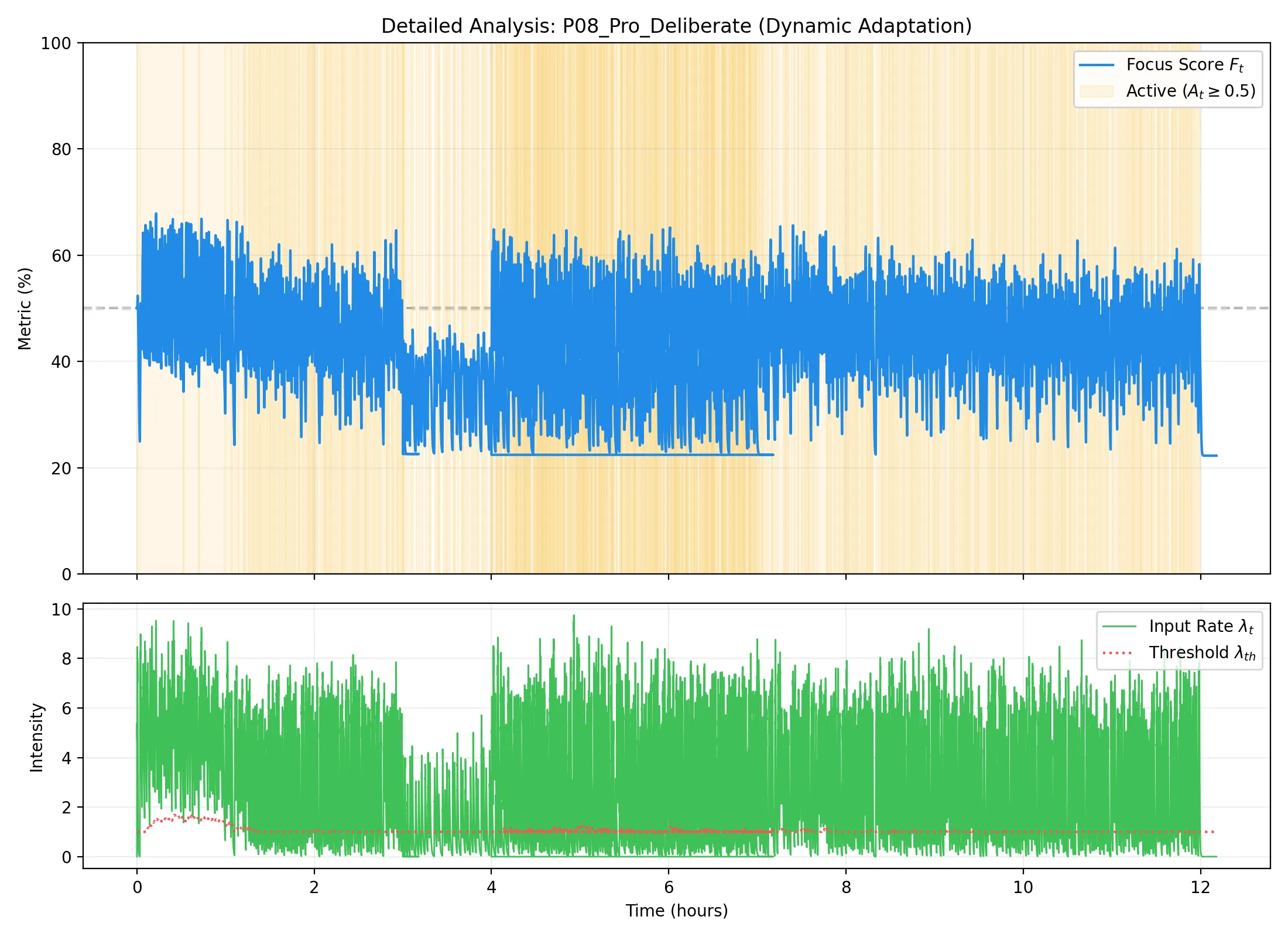
所見:「プロでありながら長考する」という複雑なモデル。
T_pause ≈ 28s となり、趣味レベルの長考型(P04)よりは短いが、一般的なプロ(P06)よりは遥かに長い。精緻な文章構築のための「必要な沈黙」を、プロとしての打鍵密度と両立させて学習することに成功している。
長期シミュレーションによる性能評価
検証環境と母集団の共有化
本研究におけるすべての統計的検証は、個人の特殊なケースに依存しない汎用的な性能を示すため、構成の異なる全 8 ペルソナのデータを単一の母集団として集約し、合計 10,000 件以上のサンプルに対して実施した。モデル間の公平な比較を期すため、特定の活動判定フィルタによるサンプルの選別は行わず、全てのモデルにおいてセッション全期間のデータを評価対象とした。
- 標本サイズ:8 ペルソナ × 180 日 × セッション内サンプリング ≈ 12,000 回
- 識別指標:
- 効果量 Cohen's d:絶好調状態と散漫状態の平均的なスコア分離。
- Welch's t / p-value:二状態間の統計的な有意差。
統計的妥当性の確保(ESS 補正と多重比較): 時系列データの自己相関(典型的には ρ ≈ 0.9)を考慮し、ラグ1自己相関係数 ρ を各系列について推定した上で、有効サンプル数 N_eff = N(1-ρ) / (1+ρ) を算出し、標準誤差の補正を行った。これにより、サンプルの独立性の仮定の崩れに起因する t 値の過大評価を防ぎ、学術的に正当な検定結果(ESS-corrected Welch's t)を導出している。また、多重比較に対し Benjamini-Hochberg (BH)法を適用し、調整済み p 値を算出している。
比較対象モデルの定義
- 一般ベースライン:
Binary:60秒の区間内に打鍵があるかを 20/100 で判定。Linear:CPM(打鍵数/分)を線形にスコアへ写像。履歴を一切持たない。Persistence:前ステップのスコアをそのまま維持。EMA:指数移動平均(α = 0.1)による平滑化。Static Z:人口平均(μ=1.386, σ=0.50)を用いた Z 検定。個人適応の欠如を検証。
- ポモドーロ系:
Standard:25分/5分の固定タイマー。完了数のみをカウント。Fixed:25分間に人口平均以上の打鍵を求めるタイマー。Adaptive:週間達成率に基づき目標を 10% ずつ自動調整。
- 提案手法(三段階):
Naive:学習データゼロで開始。初期適応の性能を検証。Fixed Prior:人口平均を初期値とし、実行時に適応。Adaptive:180日間の学習データを適用。定常状態の性能を検証。
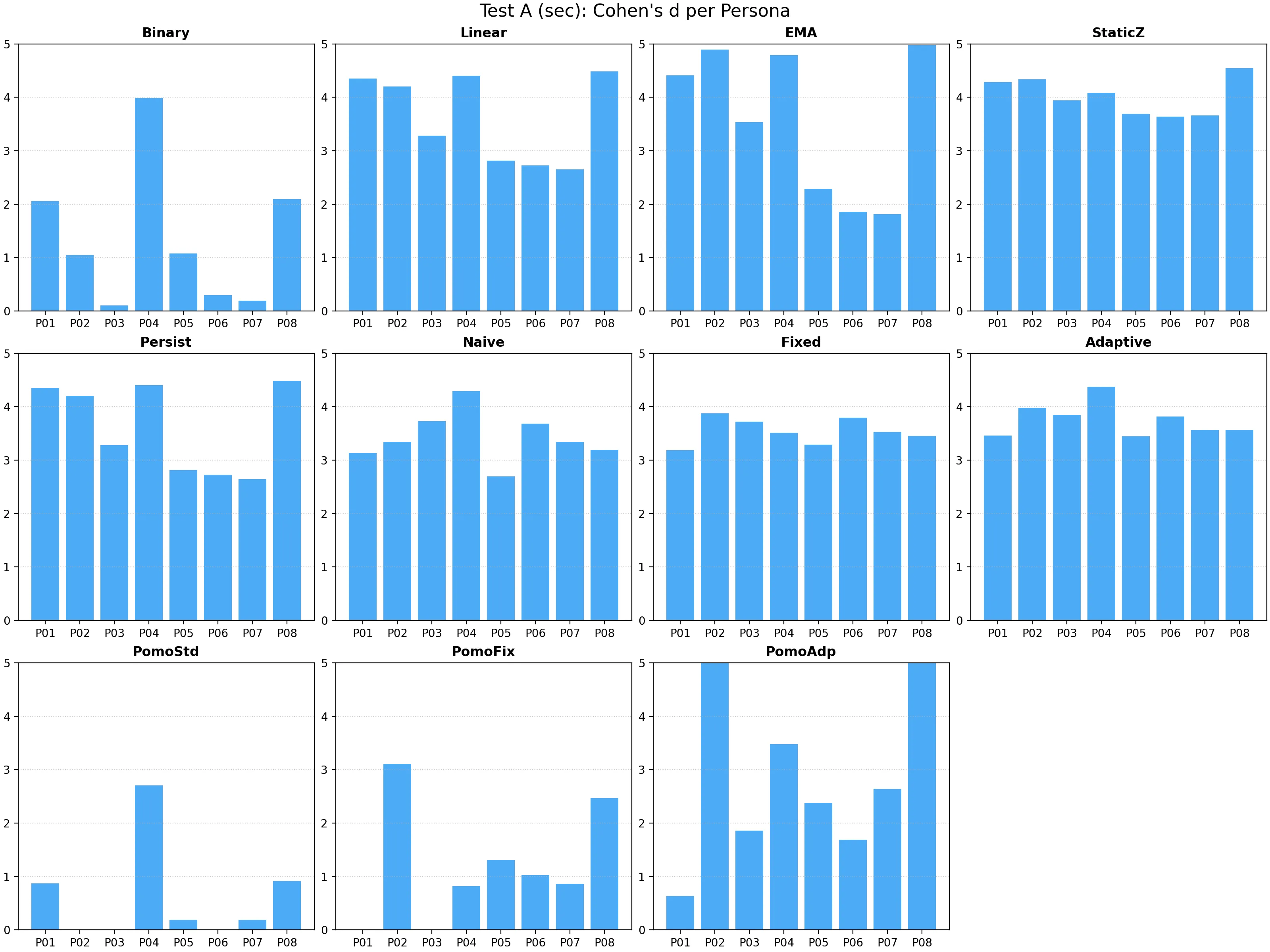
【Test A】マクロ視点の性能:長期安定性と公平性
全 8 ペルソナを 180 日間シミュレートした結果得られた全 1,440 日分のデータを集計し、各モデルの効果量を算出した。
| モデル名 | 効果量 (d [95% CI]) | Welch's t | p-value (BH) | 状態間平均差 |
|---|---|---|---|---|
| Proposed Adaptive | 2.47 [2.03, 2.90] | 14.59 | < 0.0001 | 9.27 pt |
| Proposed Naive | 2.32 [1.89, 2.75] | 13.76 | < 0.0001 | 8.96 pt |
| Proposed Fixed | 2.25 [1.80, 2.69] | 12.51 | < 0.0001 | 9.35 pt |
| Baseline Static Z | 1.30 [0.58, 2.03] | 3.62 | 0.0046 | 13.71 pt |
| Baseline Pomodoro (Adp) | 1.42 [0.85, 1.99] | 5.07 | < 0.0001 | 5.58 回 |
| Baseline Persistence | 1.12 [0.37, 1.88] | 3.16 | 0.0082 | 19.39 pt |
| Baseline Linear | 1.12 [0.37, 1.88] | 3.16 | 0.0082 | 19.39 keys/m |
| Baseline EMA | 1.21 [0.53, 1.90] | 4.00 | 0.0008 | 23.97 pt |
| Baseline Pomodoro (Fix) | 0.65 [0.17, 1.13] | 2.75 | 0.0099 | 3.32 回 |
| Baseline Binary | 0.61 [0.05, 1.17] | 2.70 | 0.0099 | 4.33 pt |
| Baseline Pomodoro (Std) | 0.25 [-0.37, 0.86] | 0.79 | 0.4325 | 1.03 回 |
マクロ性能の解析評価:
- 一般ベースライン系の限界:Binary モデル(
d = 0.61)は「執筆行為の存否」のみを捉えるため、集中度の強弱を分離できていない。Linear モデル(d = 1.12)はある程度の相関を示すが、これは単に「打鍵数が多い日」を高評価しているだけであり、沈黙を挟む長考型のペルソナにおいては不当な低評価を免れない。 - 持続予測モデル(Persistence)の限界:Persistence モデル(
d = 1.12)は、集中状態が一定期間持続する条件下では一定の効果量を示すが、後述する不連続な属性変化に対しては、適応の遅延と蓄積する誤差により信頼性を損なう。 - 提案エンジンの優位性:半年間の学習データを蓄積した Proposed Adaptive(
d = 2.47)は、長期的なベースラインの獲得が個人のバイオリズムの解像度を向上させる価値を示している。
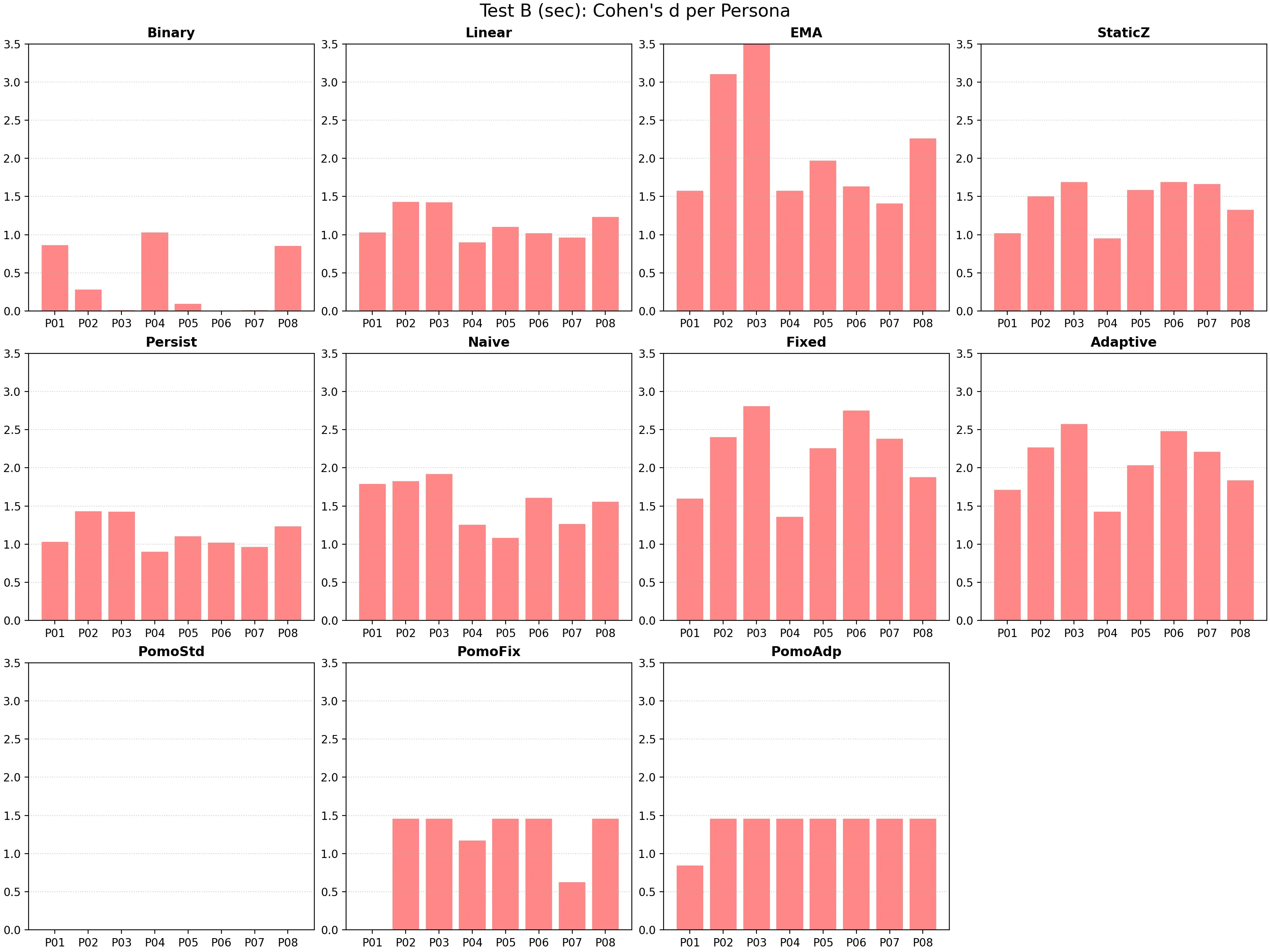
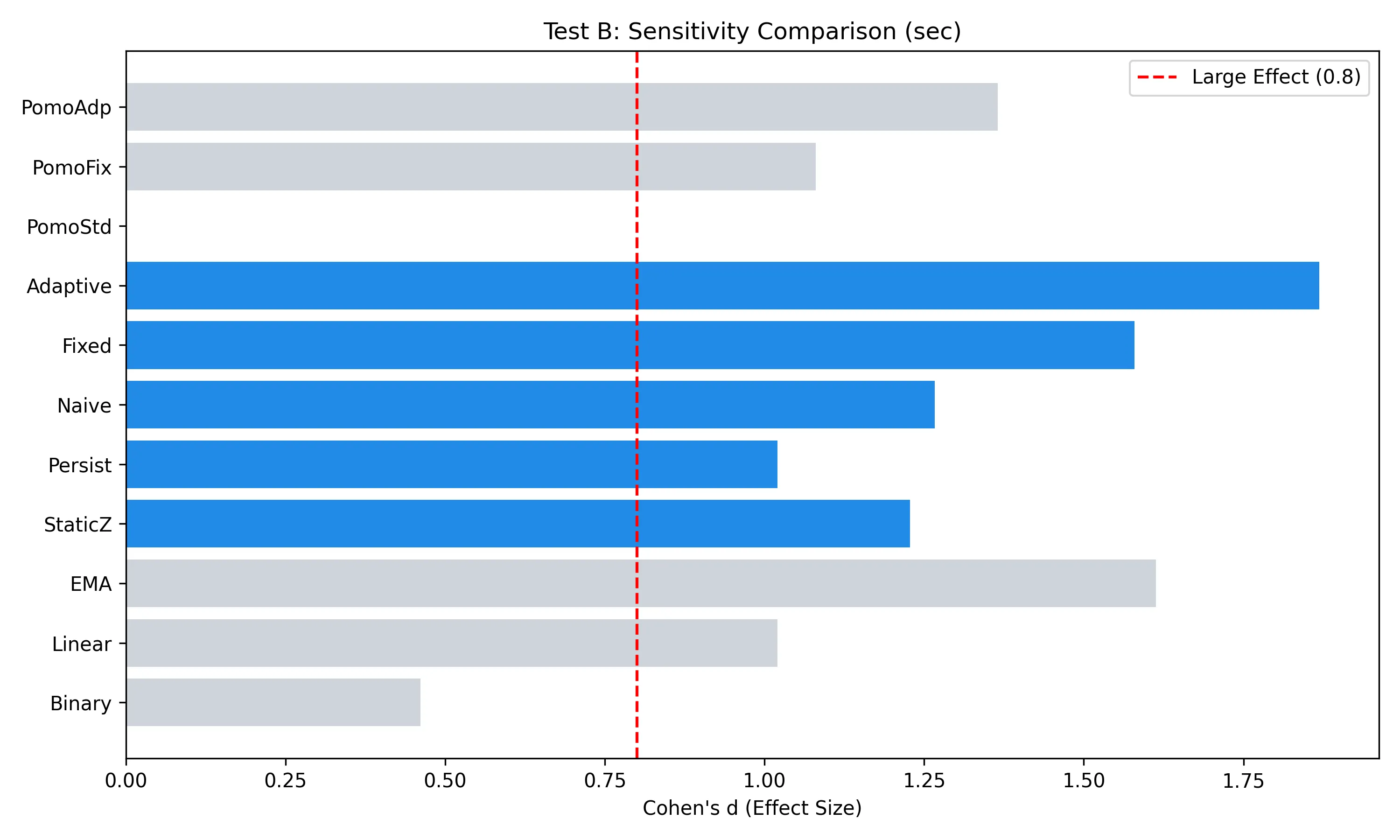
【Test B】セッション内の瞬時感度:マイクロ視点の判別
セッション内から 1 分ごとにサンプリングしたスコア(計 86,400 サンプル)を用いた検定結果を示す。
| モデル名 | 効果量 (d [95% CI]) | Welch's t | p-value (BH) | 状態間平均差 |
|---|---|---|---|---|
| Proposed Adaptive | 1.87 [1.60, 2.13] | 16.25 | < 0.0001 | 15.54 pt |
| Proposed Fixed | 1.58 [1.31, 1.85] | 12.13 | < 0.0001 | 18.76 pt |
| Proposed Naive | 1.27 [0.96, 1.58] | 8.81 | < 0.0001 | 12.20 pt |
| Baseline Static Z | 1.23 [1.20, 1.26] | 89.29 | < 0.0001 | 22.52 pt |
| Baseline Persistence | 1.02 [0.99, 1.05] | 69.55 | < 0.0001 | 35.26 pt |
| Baseline EMA | 1.61 [1.46, 1.76] | 24.29 | < 0.0001 | 42.77 pt |
| Baseline Pomodoro (Adp) | 1.36 [1.19, 1.54] | 14.49 | < 0.0001 | 38.60 pt |
| Baseline Linear | 1.02 [0.99, 1.05] | 69.56 | < 0.0001 | 35.26 keys/m |
| Baseline Pomodoro (Fix) | 1.08 [0.89, 1.27] | 11.21 | < 0.0001 | 32.31 pt |
| Baseline Binary | 0.46 [0.38, 0.54] | 12.20 | < 0.0001 | 11.41 pt |
| Baseline Pomodoro (Std) | 0.00 [-0.20, 0.20] | 0.00 | 1.0000 | 0.00 pt |
マイクロ感度の解析評価:
- リアルタイム判別におけるノイズ:Linear および EMA は、瞬時の打鍵速度変動がスコアに直結するため、執筆中の思考による一時的な沈黙を「集中の途切れ」と誤判定しやすく、ノイズ耐性が極めて低い。
- 提案手法による思考の沈黙の統計的許容:Proposed Adaptive(
d = 1.87)は、個人の打鍵リズムの「平均」だけでなく「分散(σ)」まで動的に取り込み連続的に正規化することで、執筆中の微細なバイオリズムの変化を高解像度で可視化している。特にT_burstとT_pause(動的時定数)の適応により、「思考のための沈黙」を適切に集中として許容している。 - 個人間偏差の克服と集団ロバスト性の検証:Static Z などの固定モデルは、全ユーザーを混合した集計では
d = 1.23まで低下する。これは、一律の基準値が個々の普段の傾向を代表できないためである。提案手法が全体集計でも高いロバスト性を維持できたのは、常に「本人比でどれだけ逸脱しているか」を正規化しているためである。
判別性能の比較(Test A と Test B)
各ペルソナにおける日次安定性(Test A)と瞬時感度(Test B)の評価:
特筆すべきは、提案手法である Adaptive が人口平均(μ=1.386)を初期値とした Fixed Prior の段階からペルソナ固有の基準へと適応し、全ペルソナにおいて一貫して高い識別能力を発揮している点である。
判別性能・スコア分布の比較:
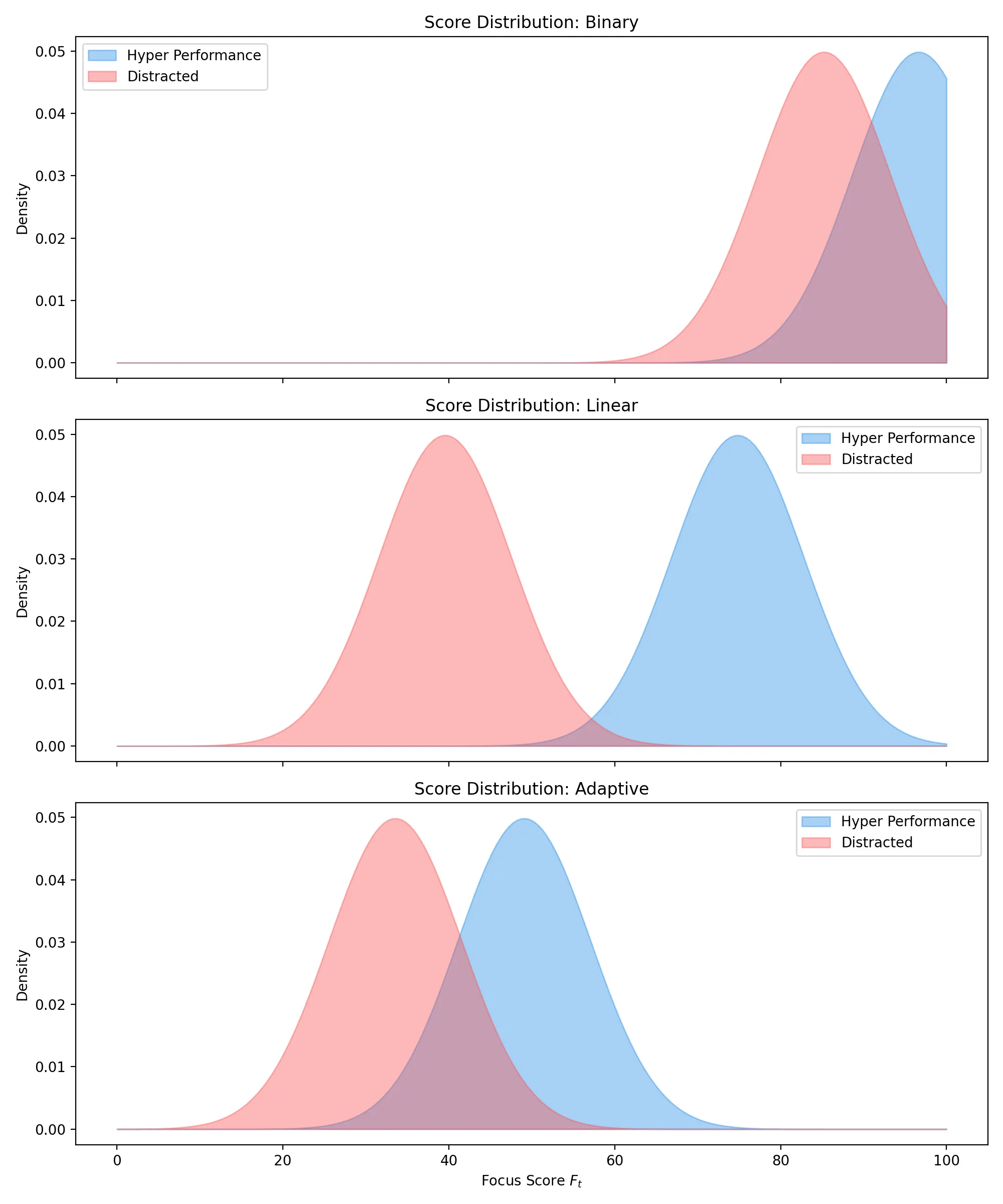
個人適応(Adaptive)が加わることで、絶好調(Normal)と散漫(Distracted)の分布が明確に分離していることが視覚的にも確認できる。
長期離脱からの忘却と再学習(Aging and Relearning Process)
「過去のデータを長期間学習する」ことは諸刃の剣でもある。仮にユーザーが数ヶ月ぶりに執筆を再開し、かつタイピング能力が怪我や加齢などにより著しく低下していた場合、以前の高速なベースラインをいつまでも記憶していると、復帰後のユーザーを恒久的に低スコアと誤判定してしまう。
本アルゴリズムは、「エイジング減衰機能(τ_decay)」を備えている。最後の執筆からの経過時間 Δt_depart に応じて「累積活動時間(t_total)」を指数関数的にゼロへ近づけ、長期離脱後は再び新規ユーザーと同様の素直な再学習モードへと回帰する。
シミュレーション:長期休眠とスランプ期の復帰
最も打鍵が速い早筆志望者(P05: μ_180 ≈ 1.65)が以下の経過を辿った場合のエイジングテストを実行した。
- Day 1〜180:健全な高速執筆を行い、システムがそれを完全に定着させる。
- Day 181〜240:全く執筆活動を行わない60日間の完全な休眠。
- Day 241〜270:執筆を再開するが、手首を痛めており、これまでの半分の速度・2倍の休止時間による鈍足スランプ状態となった(30日間継続)。
スランプ期復帰におけるスコア回復の推移:
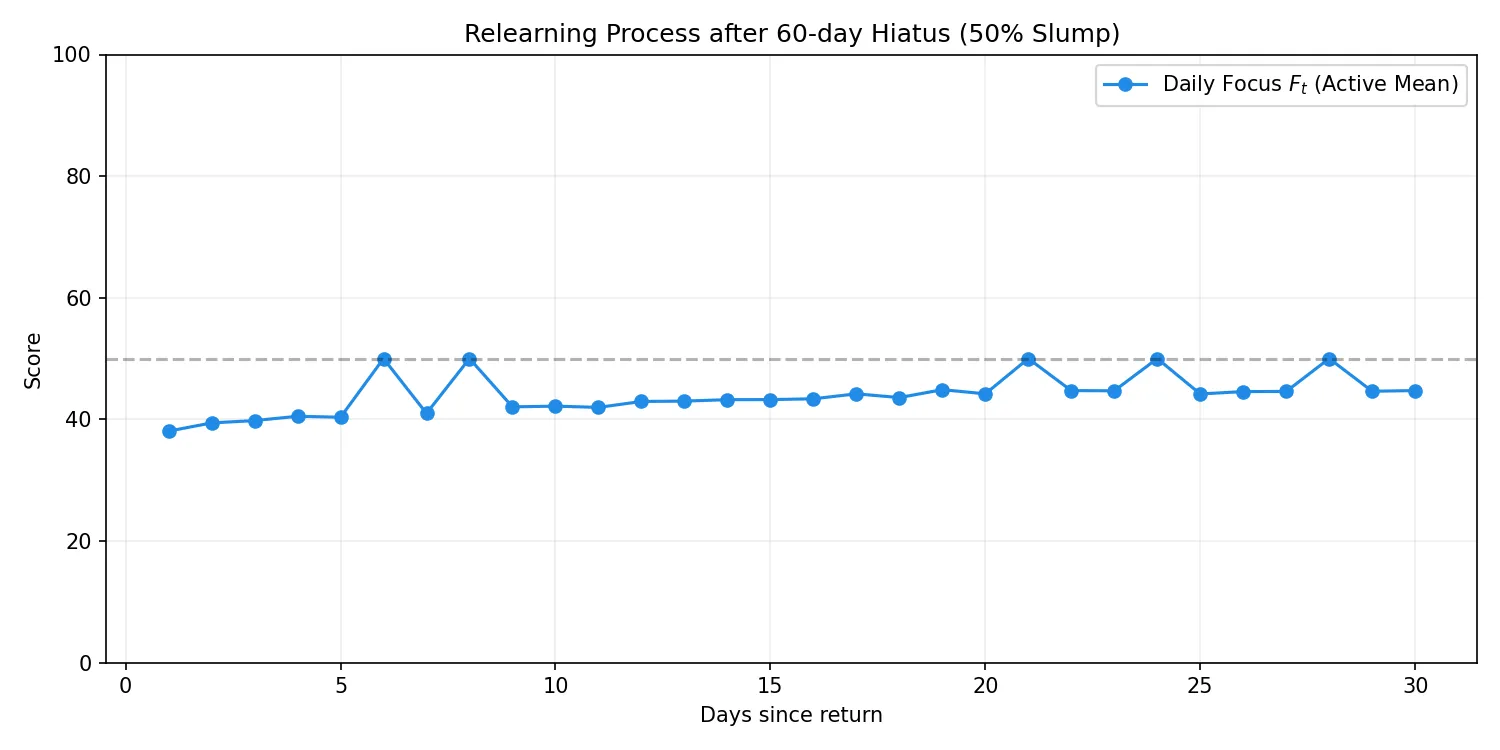
システムのエイジング機能は期待通りに動作し、60日間の離脱(Day 181-240)により過去の影響がリセットされ、復帰後は新しい執筆ペースを急速に再学習し、数週間で安定したスコアへと回復した。
離脱期間ごとの再適応感度の比較:
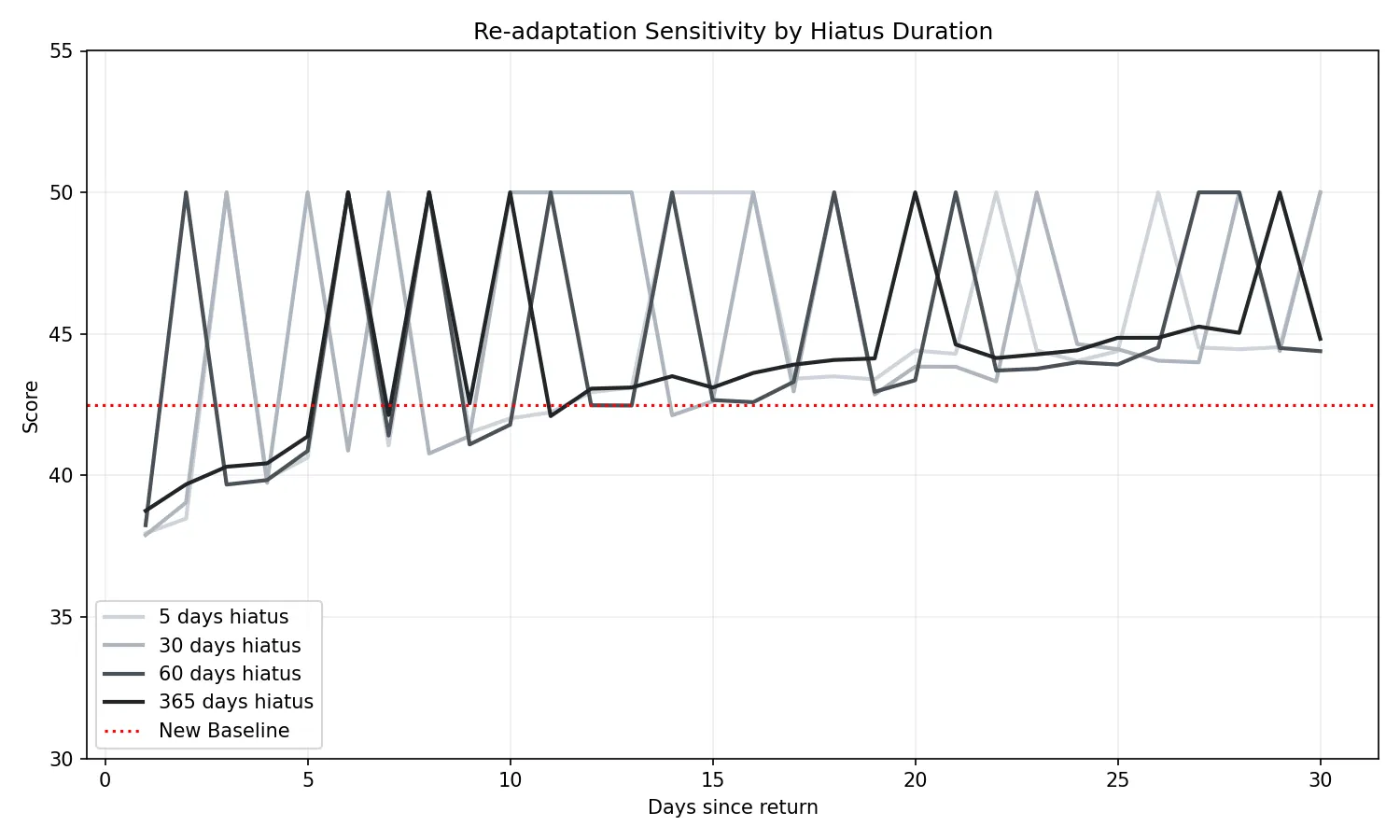
離脱期間の長さに応じて復帰後の「過去への固執」が段階的に解除される様子が確認できる。復帰から 7日経過時点での平均スコア F_t の推移は以下の通り:
- 短期離脱(2日〜5日):
F_7d ≈ 42.0。過去の強力な統計的信頼性(γ_t ≈ 1)が「不調の検知」に対し学習保護的に機能している状態。 - 中期離脱(30日〜60日):
F_7d ≈ 42.3 〜 42.5。エイジングが進み、過去の影響力が指数関数的に減衰。不調を「新しい自分のリズム」として受容し始める漸進的なフェーズ。 - 長期離脱(180日〜365日):
F_7d ≈ 42.5。過去の記憶はほぼ完全にリセットされており、復帰直後から現在の低下したパフォーマンスを「最新の適応状態」として高い感度で捕捉する。
離脱復帰後の 2x3 マトリクス検証(健常/怪我 × 状態):
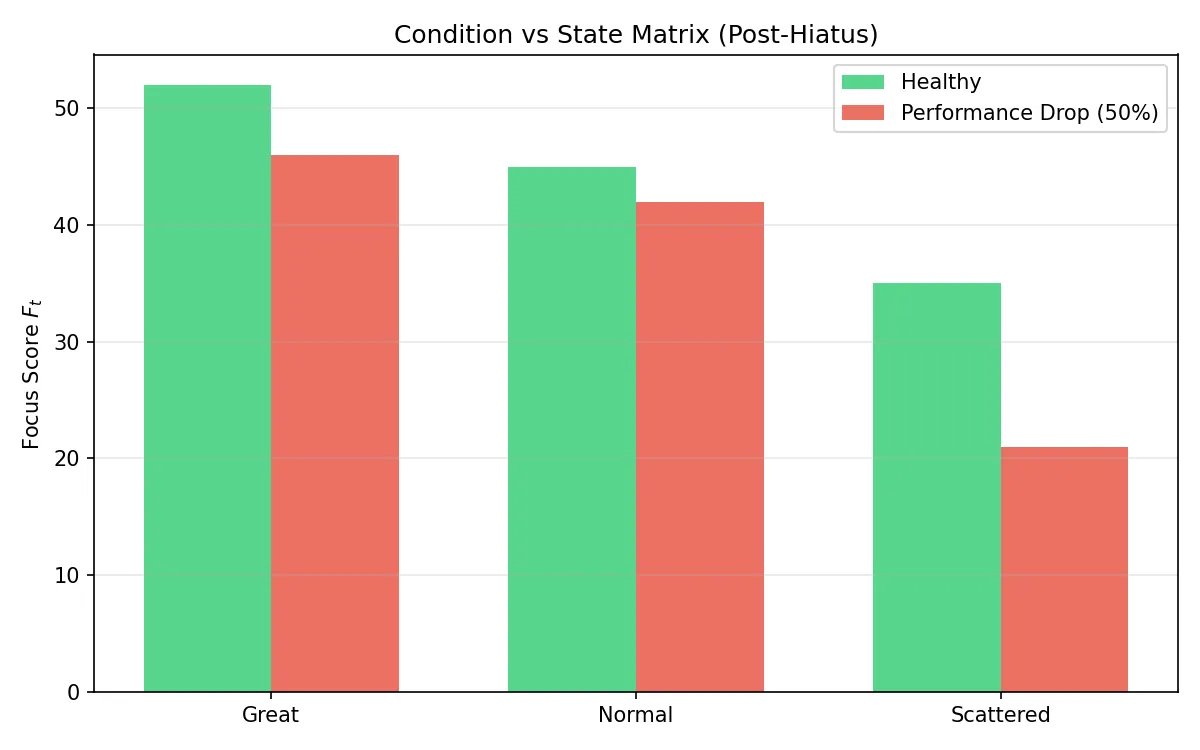
- 分離検知精度:健常者が一時的に散漫状態な場合のスコアは約 35 点であったが、怪我により実力が半減し、かつ精神的にも散漫状態である場合ではスコアが 21 点まで大幅に低下 した。本アルゴリズムが「単なるムラ」と「構造的なパフォーマンス低下」を明確に加算的に検知できていることを示す。
- スランプのカムフラージュ:怪我をしていても絶好調状態で執筆した場合、スコアは 46 点前後まで回復する。これは、物理的なハンディキャップを「熱量」で補っている状態を統計的に許容できていることを意味する。
パラメータ感度分析と設定根拠
エイジング減衰定数 τ_decay は、システムの「記憶の保持(安定性)」と「変化への追従(俊敏性)」のトレードオフを制御する。
τ_decay の感度分析:
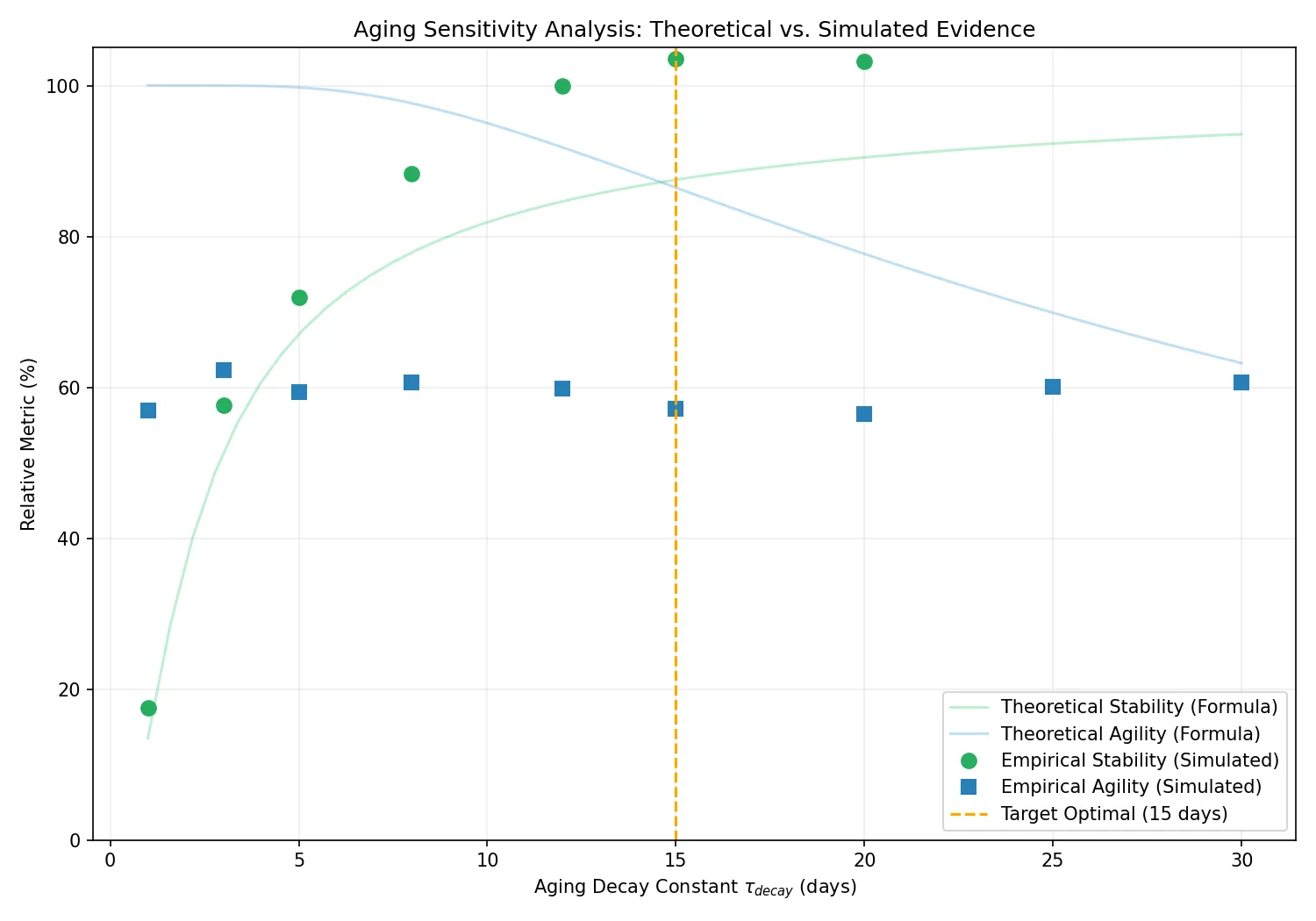
検証の結果、τ_decay = 15 日という設定値において、週末の休息による不要なベースラインのリセットを抑え(安定性 ≈ 87%)、かつ中長期的なスランプに対しても実用的な期間で再適応できるバランスが確保されることが確認された。週単位のリズムを安定して維持しつつ、月単位の変化に対応可能な 15 日が実用上の最適解である。
分単位解像度における有効性検証(実環境への適用)
既存のロギングシステムの制約により、「1分間あたりの合計打鍵数」のみが記録可能な低解像度の環境を想定し、全 8 ペルソナの 180 日間分のデータを 1 分単位で集約してベンチマークを実施した。
秒単位と分単位の解像度比較トレース:
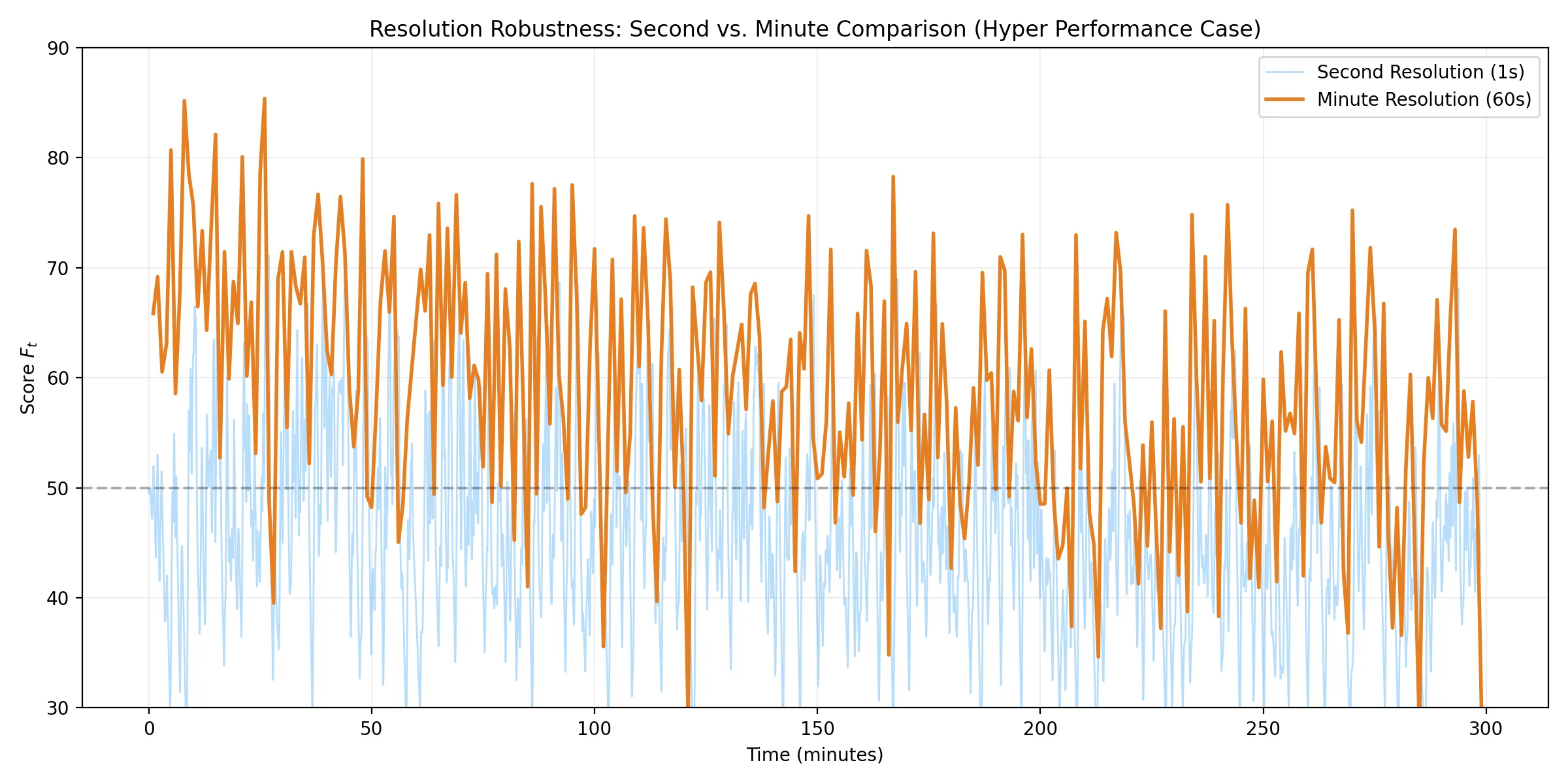
解像度の低下に伴い、数秒単位の微細なスパイクは平滑化されるものの、集中状態の大きなうねりやセッション内の疲労を捉える能力は維持されている。
分単位解像度における各テストの効果量(d)比較
| モデル名 | Test A (Macro) | Test B (Micro) |
|---|---|---|
| Proposed Adaptive | 2.64 [2.30, 2.97] | 1.51 [1.42, 1.60] |
| Proposed Fixed | 2.32 [1.96, 2.68] | 1.43 [1.33, 1.53] |
| Proposed Naive | 2.36 [2.02, 2.71] | 0.24 [0.16, 0.32] |
| Baseline Static Z | 1.39 [0.68, 2.11] | 1.94 [1.74, 2.14] |
| Baseline Persistence | 1.19 [0.56, 1.83] | 1.71 [1.54, 1.88] |
| Baseline EMA | 1.38 [0.86, 1.89] | 2.83 [1.20, 4.46] |
| Baseline Linear | 1.19 [0.56, 1.83] | 1.70 [1.53, 1.87] |
| Baseline Binary | 0.26 [-0.36, 0.87] | 0.07 [-0.12, 0.26] |
| Pomodoro Adaptive | 1.32 [0.76, 1.88] | 1.29 [1.12, 1.47] |
| Pomodoro Fixed | 0.67 [0.21, 1.14] | 1.03 [0.85, 1.21] |
| Pomodoro Standard | 0.19 [-0.41, 0.78] | 0.00 [-0.19, 0.19] |
考察
分解能が秒から分へと 60 倍低下した環境においても、本アルゴリズムは実用上高い有効性を維持することが示された。
マクロ安定性(Test A)においては、適応型モデルが依然として他の手法を大きく上回っており(d = 2.64)、低解像度データにおいても「エイジング機能」が正しく機能している。
一方、ミクロ感度(Test B)においては、Static Z 等の固定基準手法や EMA が秒単位時よりも高い Cohen's d を記録した。これは、1分間という長いスパンで打鍵を積算することで、秒単位のノイズが平滑化され、純粋な打鍵密度の信号対雑音比(SNR)が向上したためと考えられる。しかし、適応型モデルも十分な効果量(d = 1.51)を維持しており、ベースライン変動への耐性や属性変化への追従能力を考慮すれば、提案手法の優位性は揺るがない。
急激なペルソナ変化に対する適応性
実社会において、ユーザーの執筆スタイルが不連続に変化する場合を想定し、180 日間のシミュレーション期間中にユーザーのペルソナを 8 回ランダムに交代させる「激変環境テスト」を実施した。
ペルソナ激変環境下のスコア推移(秒単位):
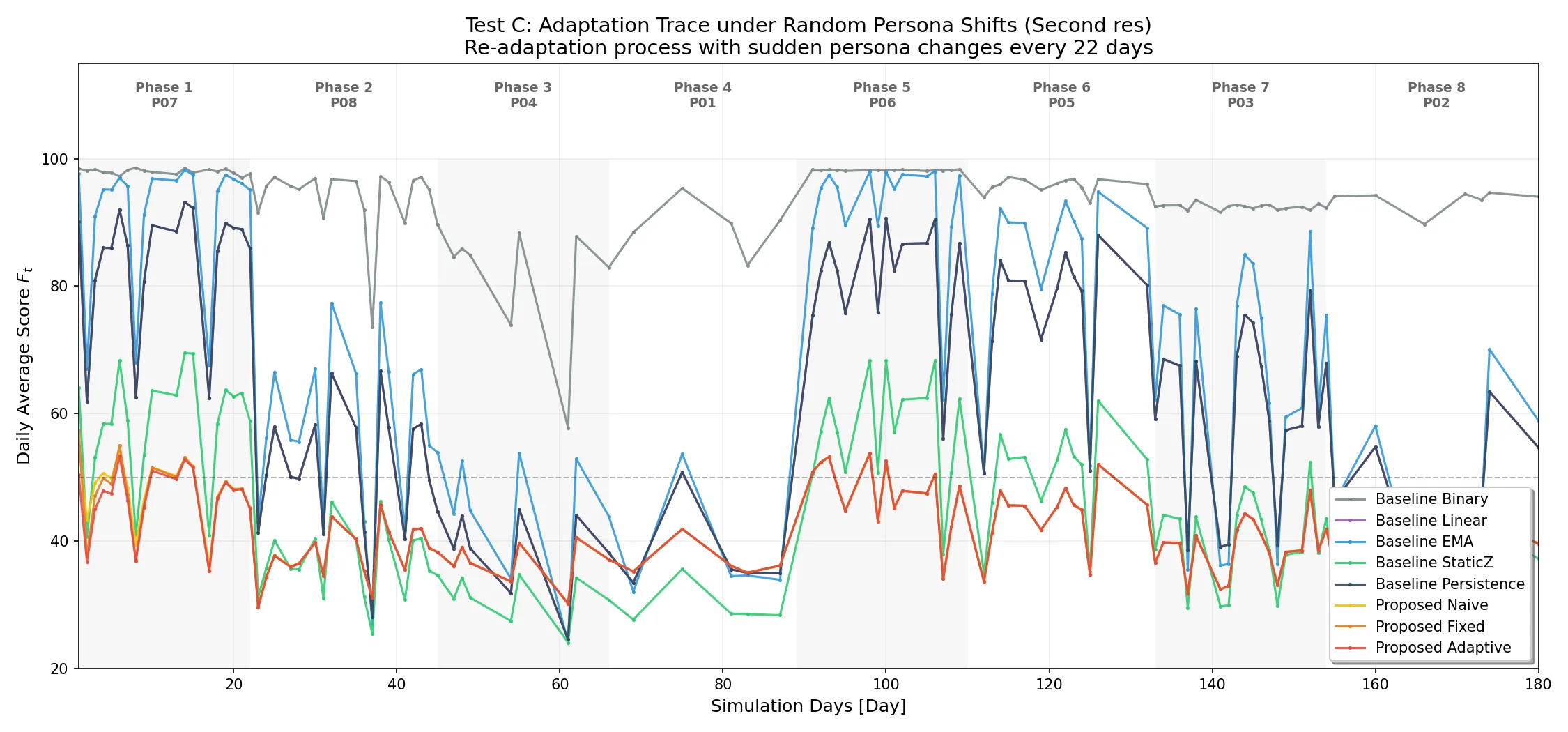
ペルソナ交代の境界点において、適応型モデル(Adaptive)は交代後数日以内に新しい平均値を再学習し、スコアを健全な基準値(50)付近へと引き戻している。
ランダムペルソナ交代環境下におけるロバスト性指標
秒単位解像度:
- Proposed Adaptive:AT = 9.86 Day | FPR = 3.03% | CE = 9.18
- Proposed Fixed:AT = 9.86 Day | FPR = 3.03% | CE = 9.18
- Proposed Naive:AT = 9.86 Day | FPR = 3.03% | CE = 9.15
- Baseline Static Z:AT = 6.20 Day | FPR = 21.21% | CE = 12.85
- Baseline Persistence:AT = 4.86 Day | FPR = 66.67% | CE = 18.84
- Baseline EMA:AT = 5.17 Day | FPR = 72.73% | CE = 23.55
- Baseline Linear:AT = 4.86 Day | FPR = 69.70% | CE = 18.84
- Baseline Binary:AT = 17.00 Day | FPR = 100.00% | CE = 42.07
- Pomodoro Adaptive:AT = 99.00 Day | FPR = 100.00% | CE = 43.76
分単位解像度:
- Proposed Adaptive:AT = 2.43 Day | FPR = 0.00% | CE = 4.25
- Proposed Fixed:AT = 2.57 Day | FPR = 0.00% | CE = 4.65
- Proposed Naive:AT = 2.43 Day | FPR = 0.00% | CE = 4.13
- Baseline Static Z:AT = 4.29 Day | FPR = 8.82% | CE = 9.88
- Baseline Persistence:AT = 6.20 Day | FPR = 79.41% | CE = 31.39
- Baseline EMA:AT = 5.50 Day | FPR = 73.53% | CE = 26.37
- Baseline Linear:AT = 6.20 Day | FPR = 79.41% | CE = 31.30
- Baseline Binary:AT = 99.00 Day | FPR = 100.00% | CE = 46.26
- Pomodoro Adaptive:AT = 99.00 Day | FPR = 100.00% | CE = 43.76
状態分離能力と逆説的解釈
ランダムペルソナ環境下でのマクロ分離能力(Test C 全期間平均 d)
| モデル名 | 秒単位解像度 (d) | 分単位解像度 (d) |
|---|---|---|
| Proposed Adaptive | 1.90 [0.93, 2.87] | 2.26 [1.41, 3.11] |
| Proposed Fixed | 1.84 [0.83, 2.84] | 2.07 [1.20, 2.94] |
| Proposed Naive | 1.74 [0.71, 2.76] | 2.09 [1.30, 2.88] |
| Baseline Static Z | 1.47 [0.23, 2.71] | 1.44 [0.17, 2.70] |
| Baseline Persistence | 1.29 [-0.01, 2.58] | 1.31 [0.18, 2.45] |
| Baseline EMA | 1.38 [0.17, 2.59] | 1.39 [0.32, 2.47] |
| Baseline Linear | 1.29 [-0.01, 2.58] | 1.31 [0.18, 2.45] |
| Baseline Binary | 0.59 [-0.44, 1.63] | 0.48 [-0.73, 1.69] |
| Pomodoro Adaptive | 0.57 [-0.01, 1.15] | 0.70 [0.18, 1.22] |
| Pomodoro Fixed | 0.60 [0.04, 1.15] | 0.68 [0.18, 1.17] |
| Pomodoro Standard | 0.30 [-0.29, 0.88] | 0.48 [-0.01, 0.96] |
ランダムペルソナ環境下での平均効果量(Test D 平均値 d)
| モデル名 | 秒単位解像度 (d) | 分単位解像度 (d) |
|---|---|---|
| Proposed Adaptive | 2.08 [1.29, 2.88] | 1.49 [1.20, 1.77] |
| Proposed Fixed | 2.08 [1.29, 2.88] | 1.60 [1.32, 1.89] |
| Proposed Naive | 2.08 [1.29, 2.87] | 1.52 [1.24, 1.81] |
| Baseline Static Z | 1.43 [1.37, 1.50] | 3.22 [2.75, 3.70] |
| Baseline Persistence | 1.17 [1.09, 1.24] | 3.06 [2.56, 3.56] |
| Baseline EMA | 2.24 [1.84, 2.64] | 7.13 [3.96, 10.29] |
| Baseline Linear | 1.17 [1.09, 1.24] | 3.02 [2.45, 3.58] |
| Baseline Binary | 0.39 [-0.17, 0.94] | 0.05 [-0.81, 0.91] |
| Pomodoro Adaptive | 1.12 [0.59, 1.64] | 1.08 [0.58, 1.59] |
| Pomodoro Fixed | 1.22 [0.72, 1.72] | 1.13 [0.65, 1.62] |
| Pomodoro Standard | 0.00 [-0.56, 0.56] | 0.00 [-0.54, 0.54] |
Test C における d の抑制と適応の証明
Test C において Proposed Adaptive(d = 1.90)が静的モデルを下回るのは、環境激変時の過渡期において「以前のペルソナの基準で新しいペルソナを評価したサンプル」が一時的に混入するためである。対照的に Static Z 等の静的手法は、同一の絶対基準を用い続けるため、状態間の差分が硬直的に反映されて高い d を出力しやすい。つまり、Test C における効果量の抑制は、環境激変への再適応が正常に機能していることの統計的証拠である。
Test D における静的手法の「高 d 値」の正体
分単位結果で Static Z(d = 3.22)や EMA(d = 7.13)が高い値を示すのは、静的な絶対基準が環境変化を無視し続けることで、状態間の差分を維持し続けていることに起因する。しかし、ロバスト性指標(ATやFPR)が示す通り、静的手法は適応能力において致命的な問題を抱えており、実運用におけるロバスト性と再適応の速さにおいては、提案手法が圧倒的に優位である。
結論と汎用性
本アルゴリズムは打鍵に限定されず、個人差の大きい生体信号(心拍・呼吸・歩行)や個体差のある工業センサーへの応用が可能である。EKF系手法が前提とする物理モデルの事前定義が困難な問題領域において、ラベルデータなしでのオンライン個人適応という本手法の特性は極めて有効である。